
Share the Memories v1.0.2 serial key or number

Share the Memories v1.0.2 serial key or number
Provisionaire Amp Editor V1.0.0 for Win 10 and firmware (2)
ATTENTION
PLEASE READ THIS SOFTWARE LICENSE AGREEMENT ("AGREEMENT") CAREFULLY BEFORE USING THIS SOFTWARE. YOU ARE ONLY PERMITTED TO USE THIS SOFTWARE PURSUANT TO THE TERMS AND CONDITIONS OF THIS AGREEMENT. THIS AGREEMENT IS BETWEEN YOU (AS AN INDIVIDUAL OR LEGAL ENTITY) AND YAMAHA CORPORATION ("YAMAHA").
BY DOWNLOADING OR INSTALLING THIS SOFTWARE OR OTHERWISE RENDERING IT AVAILABLE FOR YOUR USE, YOU ARE AGREEING TO BE BOUND BY THE TERMS OF THIS LICENSE. IF YOU DO NOT AGREE WITH THE TERMS, DO NOT DOWNLOAD, INSTALL, COPY, OR OTHERWISE USE THIS SOFTWARE. IF YOU HAVE DOWNLOADED OR INSTALLED THE SOFTWARE AND DO NOT AGREE TO THE TERMS, PROMPTLY DELETE THE SOFTWARE.
GRANT OF LICENSE AND COPYRIGHT
Yamaha hereby grants you the right to use the programs and data files composing the software accompanying this Agreement, and any programs and files for upgrading such software that may be distributed to you in the future with terms and conditions attached (collectively, “SOFTWARE”), only on a computer, musical instrument or equipment item that you yourself own or manage. While ownership of the storage media in which the SOFTWARE is stored rests with you, the SOFTWARE itself is owned by Yamaha and/or Yamaha’s licensor(s), and is protected by relevant copyright laws and all applicable treaty provisions.
RESTRICTIONS
- You may not engage in reverse engineering, disassembly, decompilation or otherwise deriving a source code form of the SOFTWARE by any method whatsoever.
- You may not reproduce, modify, change, rent, lease, or distribute the SOFTWARE in whole or in part, or create derivative works of the SOFTWARE.
- You may not electronically transmit the SOFTWARE from one computer to another or share the SOFTWARE in a network with other computers.
- You may not use the SOFTWARE to distribute illegal data or data that violates public policy.
- You may not initiate services based on the use of the SOFTWARE without permission by Yamaha Corporation.
Copyrighted data, including but not limited to MIDI data for songs, obtained by means of the SOFTWARE, are subject to the following restrictions which you must observe.
- Data received by means of the SOFTWARE may not be used for any commercial purposes without permission of the copyright owner.
- Data received by means of the SOFTWARE may not be duplicated, transferred, or distributed, or played back or performed for listeners in public without permission of the copyright owner.
- The encryption of data received by means of the SOFTWARE may not be removed nor may the electronic watermark be modified without permission of the copyright owner.
TERMINATION
If any copyright law or provisions of this Agreement is violated, the Agreement shall terminate automatically and immediately without notice from Yamaha. Upon such termination, you must immediately destroy the licensed SOFTWARE, any accompanying written documents and all copies thereof.
DOWNLOADED SOFTWARE
If you believe that the downloading process was faulty, you may contact Yamaha, and Yamaha shall permit you to re-download the SOFTWARE, provided that you first destroy any copies or partial copies of the SOFTWARE that you obtained through your previous download attempt. This permission to re-download shall not limit in any manner the disclaimer of warranty set forth in Section 5 below.
DISCLAIMER OF WARRANTY ON SOFTWARE
You expressly acknowledge and agree that use of the SOFTWARE is at your sole risk. The SOFTWARE and related documentation are provided "AS IS" and without warranty of any kind. NOTWITHSTANDING ANY OTHER PROVISION OF THIS AGREEMENT, YAMAHA EXPRESSLY DISCLAIMS ALL WARRANTIES AS TO THE SOFTWARE, EXPRESS, AND IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT OF THIRD PARTY RIGHTS. SPECIFICALLY, BUT WITHOUT LIMITING THE FOREGOING, YAMAHA DOES NOT WARRANT THAT THE SOFTWARE WILL MEET YOUR REQUIREMENTS, THAT THE OPERATION OF THE SOFTWARE WILL BE UNINTERRUPTED OR ERROR-FREE, OR THAT DEFECTS IN THE SOFTWARE WILL BE CORRECTED.
LIMITATION OF LIABILITY
YAMAHA’S ENTIRE OBLIGATION HEREUNDER SHALL BE TO PERMIT USE OF THE SOFTWARE UNDER THE TERMS HEREOF. IN NO EVENT SHALL YAMAHA BE LIABLE TO YOU OR ANY OTHER PERSON FOR ANY DAMAGES, INCLUDING, WITHOUT LIMITATION, ANY DIRECT, INDIRECT, INCIDENTAL OR CONSEQUENTIAL DAMAGES, EXPENSES, LOST PROFITS, LOST DATA OR OTHER DAMAGES ARISING OUT OF THE USE, MISUSE OR INABILITY TO USE THE SOFTWARE, EVEN IF YAMAHA OR AN AUTHORIZED DEALER HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. In no event shall Yamaha's total liability to you for all damages, losses and causes of action (whether in contract, tort or otherwise) exceed the amount paid for the SOFTWARE.
THIRD PARTY SOFTWARE
Third party software and data ("THIRD PARTY SOFTWARE") may be attached to the SOFTWARE. If, in the written materials or the electronic data accompanying the Software, Yamaha identifies any software and data as THIRD PARTY SOFTWARE, you acknowledge and agree that you must abide by the provisions of any Agreement provided with the THIRD PARTY SOFTWARE and that the party providing the THIRD PARTY SOFTWARE is responsible for any warranty or liability related to or arising from the THIRD PARTY SOFTWARE. Yamaha is not responsible in any way for the THIRD PARTY SOFTWARE or your use thereof.
- Yamaha provides no express warranties as to the THIRD PARTY SOFTWARE. IN ADDITION, YAMAHA EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE, as to the THIRD PARTY SOFTWARE.
- Yamaha shall not provide you with any service or maintenance as to the THIRD PARTY SOFTWARE.
- Yamaha is not liable to you or any other person for any damages, including, without limitation, any direct, indirect, incidental or consequential damages, expenses, lost profits, lost data or other damages arising out of the use, misuse or inability to use the THIRD PARTY SOFTWARE.
U.S. GOVERNMENT RESTRICTED RIGHTS NOTICE:
The Software is a "commercial item," as that term is defined at 48 C.F.R. 2.101 (Oct 1995), consisting of "commercial computer software" and "commercial computer software documentation," as such terms are used in 48 C.F.R. 12.212 (Sept 1995). Consistent with 48 C.F.R. 12.212 and 48 C.F.R. 227.7202-1 through 227.72024 (June 1995), all U.S. Government End Users shall acquire the Software with only those rights set forth herein
GENERAL
This Agreement shall be interpreted according to and governed by Japanese law without reference to principles of conflict of laws. Any dispute or procedure shall be heard before the Tokyo District Court in Japan. If for any reason a court of competent jurisdiction finds any portion of this Agreement to be unenforceable, the remainder of this Agreement shall continue in full force and effect.
COMPLETE AGREEMENT
This Agreement constitutes the entire agreement between the parties with respect to use of the SOFTWARE and any accompanying written materials and supersedes all prior or contemporaneous understandings or agreements, written or oral, regarding the subject matter of this Agreement. No amendment or revision of this Agreement will be binding unless in writing and signed by a fully authorized representative of Yamaha.
Infoblox spoke v1.0.2
Automate network management tasks in Infoblox from your ServiceNow instance. For example, register or delete IP addresses on an Infoblox server.
Request apps on the Store
Visit the ServiceNow Store website to view all the available apps and for information about submitting requests to the store. For cumulative release notes information for all released apps, see the ServiceNow Store version history release notes.
IntegrationHub subscription
This spoke requires the IntegrationHub Standard subscription package. For more information, see Request IntegrationHub.
Supported version
Infoblox versions 2.7 and 2.9.
Spoke flows
The Infoblox spoke provides sample flows in the draft state to automate allocating IP addresses in the Infoblox grid server. To customize a sample flow, copy it to a new application scope. Available sample flows include:
| Flow | Description |
|---|---|
| Infoblox Register or Reserve IP in IPAM | Registers or reserves an IP address in Infoblox based on a Service Catalog item request. |
Spoke subflows
The Infoblox spoke provides sample subflows to register and reserve IP addresses.
| Flow | Description |
|---|---|
| Register AName Record and Get Network Details | Registers an AName record type in the DNS server and retrieves network details such as network options and ID. |
Spoke actions
The Infoblox spoke provides actions to manage IP addresses and networks in Infoblox from your ServiceNow instance. Available actions include:
| Category | Action | Description |
|---|---|---|
| DHCP | Delete IP Reservation | Deletes IP address range from an Infoblox server. |
| List IP Address Reservation | Lists IP address reservation in the DHCP server for a given Infoblox network view. | |
| Reserve IP Address Range | Reserves an IP address range in the Infoblox server. | |
| DNS | List CName Records | Lists CName records present in the Infoblox server. |
| List DNS Records | Lists DNS records present in the Infoblox server. | |
| Register AName Record | Registers an AName record type in DNS server. An AName record stores mapping between the fully qualified domain name and the IP address. | |
| Register CName Record | Registers a CName record in the Infoblox DNS Server. A CName record is an alias to the fully qualified domain name. | |
| Delete DNS Record | Deletes a DNS record in the Grid Server. | |
| IPAM | Delete IPAM IP Address Reservation | Deletes an IPAM IP address Reservation in Infoblox. |
| List all the IPAM Reservations | Lists the IP addresses within a given Infoblox Server. | |
| Register IPAM IP Address | Registers the IP addresses within a given Infoblox Server. | |
| Reserve IPAM IP Addresses | Reserves the IP addresses within a given Infoblox Server. | |
| Network | Create Network | Creates a network within a given Infoblox Server. |
| Delete Network | Deletes a network within a given Infoblox Server. | |
| Get Network Details | Gets the network details within a given Infoblox Server. |
Connection and credential alias requirements
IntegrationHub uses aliases to manage connection and credential information. Using an alias eliminates the need to configure multiple credentials and connection information profiles when using multiple environments. If the connection or credential information changes, you don't need to update any actions that use the connection. For more information, see Connections and Credentials.
This spoke uses the Infoblox alias record to authorize actions.
| Connection & Credential alias | Description | Connection alias requirements |
|---|---|---|
| Infoblox | Connection to Infoblox server |
|
To use the spoke connection alias, create an associated Connection record and an associated Credential record.
MID Server requirements
These actions use REST calls, which must run on a MID Server. Use the connection record associated with the Infoblox alias to configure where actions run as well as set MID Server selection attributes. For more information, see MID server.
InfluxDB 1.8 release notes
See the equivalent InfluxDB v2.0 documentation:InfluxDB v2.0 release notes.
v1.8.2 [2020-08-13]
Bug fixes
- Revert configuration change to that caused some environments to experience increased memory usage.
v1.8.1 [2020-07-14]
Bug that potentially increased memory usage was introduced in 1.8.1. If you installed this release, install v1.8.2, which includes the features, performance improvements, and bug fixes below.
Features
- Allow users to add custom HTTP response headers to comply with internal security policies.
Performance improvements
- InfluxQL query planner plans each field in parallel to improve planning time.
- Improved performance of DELETE/DROP by batching tombstone writes.
Bug fixes
- Fix to Flux function causing a panic.
- TSI: Addressed a couple of edge cases which resulted in segfaults.
- HTTP: Simplify Authorizer.
- Wait to delete epoch before dropping shard.
- Improve error handling when creating snapshots.
- Remove all Go 1.12 references from build.
v1.8.0 [2020-4-13]
Features
Flux v0.65 ready for production use
This release updates support for the Flux language and queries. To learn about Flux design principles and see how to get started with Flux, see Introduction to Flux.
Use the new option to enable the Flux REPL shell for creating Flux queries.
Flux v0.65 includes the following capabilities:
- Join data residing in multiple measurements, buckets, or data sources
- Perform mathematical operations using data gathered across measurements/buckets
- Manipulate Strings through an extensive library of string related functions
- Shape data through and other functions
- Group based on any data column: tags, fields, etc.
- Window and aggregate based on calendar months, years
- Join data across Influx and non-Influx sources
- Cast booleans to integers
- Query geo-temporal data (experimental)
- Many additional functions for working with data
We’re evaluating the need for Flux query management controls equivalent to existing InfluxQL query management controls based on your feedback. Please join the discussion on InfluxCommunity, Slack, or GitHub. InfluxDB Enterprise customers, please contact support@influxdata.com.
Forward compatibility
- InfluxDB 2.0 API compatibility endpoints are now part of the InfluxDB 1.x line.
This allows you to leverage the new InfluxDB 2.0 client libraries for both writing and querying data with Flux. Take advantage of the latest client libraries while readying your implementation for a move to InfluxDB 2.0 Cloud when you’re ready to scale.
Operational improvements
- Add command
- Add offline series compaction to . If you’re currently using the Time Series Index (tsi1), the index files grow over time and aren’t automatically compacted. This tool enables an administrator to perform a compaction while the database is offline.
- Add support for connecting to a custom HTTP endpoint using in the CLI. This allows the Influx CLI to connect to an InfluxDB instance running behind a reverse proxy with a custom subpath endpoint.
Security enhancements
Other updates
- Update Go version to 1.13.8.
Bug fixes
- Skip during backup if is busy. This fix eliminates contention between snapshot and backup processes, allowing backups to complete more reliably.
- Rebuild the series index when data is actually deleted (not when deleted data is only found in cache or outside of time range).
- Parse Accept header correctly.
- Upgrade compaction error log from to .
- Remove double increment of index.
- Improve series cardinality limit for index.
- Ensure all block data returned.
- Reduce and startup time if Flux isn’t used.
- Fix bugs in flag.
- Fix a SIGSEGV when accessing active log.
- Verify precision in write requests.
v1.7.10 [2020-02-07]
Bug fixes
- Fix failing corrupt data file renaming process.
- Make shard digests safe for concurrent use.
- Fix defect in TSI index where negative equality filters () could result in no matching series.
- Fix compaction logic on infrequent cache snapshots which resulted in frequent full compactions rather than level compactions.
- Fix for series key block data being truncated when read into an empty buffer. Ensure all block data is returned.
- During compactions, skip TSM files with block read errors from previous compactions.
v1.7.9 [2019-10-27]
Bug fixes
- Guard against compaction burst throughput limit.
- Replace TSI compaction wait group with counter.
- Update InfluxQL dependency.
- Add option to authenticate debug/pprof and ping endpoints.
- Honor even if custom TLS config is specified.
Features
- Update Go version to 1.12.10.
- Remove Godeps file.
- Update Flux version to v0.50.2.
v1.7.8 [2019-08-20]
InfluxDB now rejects all non-UTF-8 characters. To successfully write data to InfluxDB, use only UTF-8 characters in database names, measurement names, tag sets, and field sets.
Bugfixes
- Fix Prometheus read panic.
- Remove stray in .
- Fix issue where fields re-appear after .
- Remove a dubugging call.
- Subquery ordering with aggregates in descending mode was wrong.
- Fix the http handler to not mislabel series as partial.
- Make count only distinct series.
- Fix time range exceeding min/max bounds.
Features
- Update Flux version to v0.36.2
1.7.7 [2019-06-26]
Known issues
- The Flux Technical Preview was not advanced and remains at version 0.24.0. Next month’s maintenance release will update the preview.
- After upgrading, customers have experienced an excessively large output additional lines due to a statement introduced in this release. For a possible workaround, see https://github.com/influxdata/influxdb/issues/14265#issuecomment-508875853. Next month’s maintenance release will address this.
Bug fixes
- Fix the sort order for aggregates so that they are sorted by tag and then time.
- Use the timezone when evaluating time literals in subqueries.
- Fix CSV decoder bug where empty tag values cause an array index panic.
- Fix open/close race in .
- Sync series segment after truncate.
- Fix the ordering for selectors within a subquery with different outer tags.
1.7.6 [2019-04-16]
If your InfluxDB OSS server is using the default in-memory index (), this release includes the fix for InfluxDB 1.7.5 servers that stopped responding without warning.
Features
- Upgrade Flux to and remove the platform dependency.
- If Flux is enabled, use Chronograf 1.7.11 or later.
- When using Flux, there is a known issue that using will cause a panic. The proper syntax is .
- Track remote read requests to Prometheus remote read handler.
Bug fixes
- Ensure credentials are correctly passed when executing Flux HTTP requests in the CLI with the option.
- Back port of data generation improvements: renamed files for consistency between versions, added schema option, and updated schema example documentation.
- Fix security vulnerability when configuration setting is blank.
- Add nil check for .
- Extend the Prometheus remote write endpoint to drop unsupported Prometheus values (,, and ) rather than reject the entire batch.
- If write trace logging enabled (), then summaries of dropped values are logged.
- If a batch of values contains values that are subsequently dropped, HTTP status code is returned.
- Update predicate key mapping to match InfluxDB behavior.
- Fix panic in Prometheus read API.
- Add a version constraint for influxql.
1.7.5 [2019-03-26]
Update (2019-04-01): If your InfluxDB OSS server is using the default in-memory index (), then do not upgrade to this release. Customers have reported that InfluxDB 1.7.5 stops responding without warning. For details, see GitHub issue #13010. The planned fix will be available soon.
Bug fixes
- Update mutex to write lock.
- Fix some more shard epoch races.
1.7.4 [2019-02-13]
Features
Bug fixes
- Remove copy-on-write when caching bitmaps in TSI.
- Use for Amazon Linux 2.
- Revert “Limit force-full and cold compaction size.”
- Convert to use string fields.
- Ensure that cached series id sets are Go heap backed.
1.7.3 [2019-01-11]
Important update [2019-02-13]
If you have not installed this release, then install the 1.7.4 release.
If you are currently running this release, then upgrade to the 1.7.4 release as soon as possible.
- A critical defect in the InfluxDB 1.7.3 release was discovered and our engineering team fixed the issue in the 1.7.4 release. Out of high concern for your data and projects, upgrade to the 1.7.4 release as soon as possible.
- Critical defect: Shards larger than 16GB are at high risk for data loss during full compaction. The full compaction process runs when a shard go “cold” – no new data is being written into the database during the time range specified by the shard.
- Post-mortem analysis: InfluxData engineering is performing a post-mortem analysis to determine how this defect was introduced. Their discoveries will be shared in a blog post.
Breaking changes
- Fix invalid UTF-8 bytes preventing shard opening. Treat fields and measurements as raw bytes.
Features
Bug fixes
- Limit force-full and cold compaction size.
- Add user authentication and authorization support for Flux HTTP requests.
- Call API to correctly map group mode.
- Marked functions that always return floats as always returning floats.
- Add support for optionally logging Flux queries.
- Fix cardinality estimation error.
1.7.2 [2018-12-11]
Bug fixes
- Update to Flux 0.7.1.
- Conflict-based concurrency resolution adds guards and an epoch-based system to coordinate modifications when deletes happen against writes to the same points at the same time.
- Skip and warn that series file should not be in a retention policy directory.
- Checks if measurement was removed from index, and if it was, then cleans up out of fields index. Also fix cleanup issue where only prefix was checked when matching measurements like “m1” and “m10”.
- Error message to user that databases must be run in non-mixed index mode to allow deletes.
- Update platform dependency to simplify Flux support in Enterprise.
- Verify series file in presence of tombstones.
- Fix when a type that implements Unmarshaler is in a slice to not call when the environment variable is set to empty.
- Drop NaN values when writing back points and fix the point writer to report the number of points actually written and omits the ones that were dropped.
- Query authorizer was not properly passed to subqueries so rejections did not happen when a subquery was the one reading the value. Max series limit was not propagated downward.
1.7.1 [2018-11-14]
Bug fixes
- Simple8B incorrectly encodes entries: For a run of , if the 120th or 240th entry is not a , the run will be incorrectly encoded as selector () or selector (), resulting in a loss of data for the 120th or 240th value. Manifests itself as consuming significant CPU resources and as compactions running indefinitely.
1.7.0 [2018-11-06]
Breaking changes
Chunked query was added into the Go client v2 interface. If you compiled against the Go client v2 previously, you need to recompile using the updated interface.
Features
Flux v0.7 technical preview
Support for the Flux language and queries has been added in this release. To begin exploring Flux 0.7 (technical preview):
- Enable Flux using the new configuration setting .
- Use the new option to enable the Flux REPL shell for creating Flux queries.
- Read about Flux and the Flux language, enabling Flux, or jump into the getting started and other guides.
Time Series Index (TSI) query performance and throughputs improvements
- Faster index planning for queries against indexes with many series that share tag pairs.
- Reduced index planning for queries that include previously queried tag pairs — the TSI index now caches partial index results for later reuse.
- Performance improvements required a change in on-disk TSI format to be used.
- To take advantage of these improvements:
- Rebuild your indexes or wait for a TSI compaction of your indexes, at which point the new TSI format will be applied.
- Hot shards and new shards immediately use the new TSI format.
Other features
- Enable the storage service by default.
- Ensure read service regular expressions get optimized.
- Add chunked query into the Go client v2.
- Add config setting to create an access log filter.
- Compaction performance improvements for Time Series Index (TSI).
- Add roaring bitmaps to TSI index files.
Bug fixes
- Missing in v1 generation.
- Fix the inherited interval for derivative and others.
- Fix subquery functionality when a function references a tag from the subquery.
- Strip tags from a subquery when the outer query does not group by that tag.
1.6.6 [2019-02-28]
Bug fixes
- Marked functions that always return floats as always returning floats.
- Fix cardinality estimation error.
- Update mutex to write lock.
1.6.5 [2019-01-10]
Features
- Reduce allocations in TSI implementation.
Bug fixes
- Fix panic in .
- Pass the query authorizer to subqueries.
- Fix TSM1 panic on reader error.
- Limit database and retention policy names to 255 characters.
- Update Go runtime to 1.10.6.
1.6.4 [2018-10-16]
Features
- Set maximum cache size using in when building TSI index.
Bug fixes
- Fix sketch locking.
- Fix subquery functionality when a function references a tag from the subquery.
- Strip tags from a subquery when the outer query does not group by that tag.
- Add flag to command help.
- Cleanup failed TSM snapshots.
- Fix TSM1 panic on reader error.
- Fix series file tombstoning.
- Fixing the stream iterator to not ignore the error.
- Do not panic when a series ID iterator is nil.
- Fix append of possible nil iterator.
1.6.3 [2018-09-14]
Features
- Remove TSI1 HLL sketches from heap.
Bug fixes
- Fix the inherited interval for derivative and others. The inherited interval from an outer query should not have caused an inner query to fail because inherited intervals are only implicitly passed to inner queries that support group by time functionality. Since an inner query with a derivative doesn’t support grouping by time and the inner query itself doesn’t specify a time, the outer query shouldn’t have invalidated the inner query.
- Fix the derivative and others time ranges for aggregate data. The derivative function and others similar to it would preload themselves with data so that the first interval would be the start of the time range. That meant reading data outside of the time range. One change to the shard mapper made in v1.4.0 caused the shard mapper to constrict queries to the intervals given to the shard mapper. This was correct because the shard mapper can only deal with times it has mapped, but this broke the functionality of looking back into the past for the derivative and other functions that used that functionality. The query compiler has been updated with an additional attribute that records how many intervals in the past will need to be read so that the shard mapper can include extra times that it may not necessarily read from, but may be queried because of the above described functionality.
1.6.2 [2018-08-27]
Features
- Reduce allocations in TSI TagSets implementation.
Bug fixes
- Ensure orphaned series cleaned up with shard drop.
1.6.1 [2018-08-03]
Features
- Improve LogFile performance with bitset iterator.
- Add TSI index cardinality report to .
- Update to Go 1.10.
- Improve performance of and TSI planning.
- Improve performance of read service for single measurements.
- Remove max concurrent compaction limit.
- Provide configurable TLS options.
- Add option to hint MADV_WILLNEED to kernel.
Bug fixes
- Improve series segment recovery.
- Fix windows mmap on zero length file.
- Ensure Filter iterators executed as late as possible.
- Document UDP precision setting in config.
- Allow tag keys to contain underscores.
- Fix a panic when matching on a specific type of regular expression.
1.6.0 [2018-07-05]
Breaking changes
- If math is used with the same selector multiple times, it will now act as a selector rather than an aggregate. See #9563 for details.
- For data received from Prometheus endpoints, every Prometheus measurement is now stored in its own InfluxDB measurement rather than storing everything in the measurement using the Prometheus measurement name as the label.
Features
- Support proxy environment variables in the client.
- Implement basic trigonometry functions.
- Add ability to delete many series with predicate.
- Implement , , and functions.
- Add more math functions to InfluxQL.
- Allow customizing the unix socket group and permissions created by the server.
- Add option to disable the write log when the log is enabled.
- Add additional technical analysis algorithms.
- Validate points on input.
- Log information about index version during startup.
- Add key sanitization to command in utility.
- Optimize the function to process points iteratively instead of in batch.
- Allow math functions to be used in the condition.
- Add HTTP write throttle settings: , , and .
- Implement .
- Add command to utility.
- Improve the number of regex patterns that are optimized to static OR conditions.
Bug fixes
- Support setting the log level through the environment variable.
- Fix panic when checking fieldsets.
- Ensure correct number of tags parsed when commas used.
- Fix data race in WAL.
- Allow kill.
- Revert “Use MADV_WILLNEED when loading TSM files”.
- Fix regression to allow now() to be used as the group by offset again.
- Delete deleted shards in retention service.
- Ignore index size in .
- Enable casting values from a subquery.
- Avoid a panic when using show diagnostics with text/csv.
- Properly track the response bytes written for queries in all format types.
- Remove error for series file when no shards exist.
- Fix the validation for multiple nested distinct calls.
- TSM: blocks until reads complete.
- Return the correct auxiliary values for and .
- Close TSMReaders from after releasing FileStore mutex.
1.5.5 [2018-12-19]
Features
- Reduce allocations in TSI implementation.
Bug fixes
- Copy return value of .
- Ensure orphaned series cleaned up with shard drop.
- Fix the derivative and others time ranges for aggregate data.
- Fix the stream iterator to not ignore errors.
- Do not panic when a series ID iterator is .
- Fix panic in .
- Pass the query authorizer to subqueries.
- Fix TSM1 panic on reader error.
1.5.4 [2018-06-21]
Features
- Add command for bulk deletes of measurements in raw TSM files.
Bug fixes
- Fix panic in readTombstoneV4.
- buildtsi: Do not escape measurement names.
1.5.3 [2018-05-25]
Features
- Add configuration setting immediately on startup. Useful for debugging startup performance issues.
Bug fixes
- Fix the validation for multiple nested calls.
- Return the correct auxiliary values for and .
1.5.2 [2018-04-12]
Features
- Check for root user when running .
- Adjustable TSI Compaction Threshold.
Bug fixes
- backport: check for failure case where backup directory has no manifest files.
- Fix regression to allow to be used as the group by offset again.
- Revert .
- Ignore index size in .
- Fix partition key.
- Ensure that conditions are encoded correctly even if the AST is not properly formed.
1.5.1 [2018-03-20]
Bug fixes
- Allow time variable to be case insensitive again.
- Support setting the log level through the environment variable.
- Ensure correct number of tags parsed.
- Fix panic when checking fieldsets.
- Fix data race in WAL.
1.5.0 [2018-03-06]
Breaking changes
The default logging format has been changed. See Logging and tracing in InfluxDB for details.
Features
- Improve CLI connection warnings.
- Backup utility prints a list of backup files.
- Backup and restore for OSS produces and consumes data in the Enterprise-compatible backup format.
- Restore runs in online mode and does not delete existing databases.
- Export functionality using and to filter exported data by .
- Handle high cardinality deletes in TSM engine.
- Improve in-memory index startup performance for high cardinality.
- Add further TSI support for streaming and copying shards.
- Schedule a full compaction after a successful import.
- Add Prometheus endpoint.
- Add ability to generate shard digests.
- Allow setting the node ID in the InfluxDB CLI program.
Bug fixes
- Refuse extra arguments to influx CLI.
- Fix space required after regex operator. Thanks @stop-start!
- Fix .
- Fix race condition in the merge iterator close method.
- Fix query compilation so multiple nested distinct calls is allowable
- Fix CLI to allow quoted database names in use statement.
- Updated client error message when response body length is zero.
- Remove extraneous newlines from the log.
- Allow lone Boolean literals in a condition expression.
- Improve performance when writes exceed or .
- Prevent a panic when a query simultaneously finishes and is killed at the same time.
- Fix missing sorting of blocks by time when compacting.
- WAL: update behavior
1.4.3 [unreleased]
Configuration Changes
Section
: default value changed from to .
Bug fixes
- Fix higher disk I/O utilization
1.4.2 [2017-11-15]
Refer to the 1.4.0 breaking changes section if fails to start with an error.
Bug fixes
- Fix when running
1.4.1 [2017-11-13]
Bug fixes
- Fix descending cursors and range queries via IFQL RPC API.
1.4.0 [2017-11-13]
TSI Index
This feature remains experimental in this release. However, a number of improvements have been made and new meta query changes will allow for this feature to be explored at more depth than previously possible. It is not recommended for production use at this time. We appreciate all of the feedback we receive on this feature. Please keep it coming!
Breaking changes
You can no longer specify a different clause in a subquery than the one in the top level query. This functionality never worked properly, but was not explicitly forbidden.
As part of the ongoing development of the index, the implementation of a Bloom Filter, used to efficiently determine if series are not present in the index, was altered. While this significantly increases the performance of the index and reduces its memory consumption, the existing indexes created while running previous versions of the database are not compatible with 1.4.0.
Users with databases using the index must go through the following process to upgrade to 1.4.0:
- Stop .
- Remove all directories on databases using the index. With default configuration these can be found in or . It’s worth noting at this point how many different you visit.
- Run the tool using the shard’s data and WAL directories for and , respectively. Given the example in step (2) that would be .
- Repeat step (3) for each shard that needs to be converted.
- Start .
Users with existing shards, who attempt to start version 1.4.0 without following the steps above, will find the shards refuse to open and will most likely see the following error message: .
Configuration Changes
Section
- option was added with a default of . When set to , multivalue plugin data (e.g. ) will be split into separate measurements (e.g., and ). When set to , multivalue plugin will be stored as a single multi-value measurement (e.g., ).
Features
- Add command to convert existing in-memory (TSM-based) shards to the TSI (Time Series Index) format.
- Add support for the Prometheus remote read and write APIs.
- Support estimated and exact SHOW CARDINALITY commands for measurements, series, tag keys, tag key values, and field keys.
- Improve performance.
- Add command, which produces a detailed execution plan of a statement.
- Improved compaction scheduling.
- Support Ctrl+C to cancel a running query in the Influx CLI.
- Allow human-readable byte sizes in configuation file.
- Respect X-Request-Id/Request-Id headers.
- Add ‘X-Influxdb-Build’ to http response headers so users can identify if a response is from an OSS or Enterprise service.
- All errors from queries or writes are available via X-InfluxDB-Error header, and 5xx error messages will be written to server logs.
- Add to allow users to choose how multivalue plugins should be handled by the collectd service.
- Make client errors more helpful on downstream errors.
- Allow panic recovery to be disabled when investigating server issues.
- Support http pipelining for endpoint.
- Reduce allocations when reading data.
- Mutex profiles are now available.
- Batch up writes for monitor service.
- Use system cursors for measurement, series, and tag key meta queries.
- Initial implementation of explain plan.
- Include the number of scanned cached values in the iterator cost.
- Improve performance of and functions.
- Report the task status for a query.
- Reduce allocations, improve performance by simplifying loop
- Separate importer log statements to stdout and stderr.
- Improve performance of Bloom Filter in TSI index.
- Add message pack format for query responses.
- Implicitly decide on a lower limit for fill queries when none is present.
- Streaming conversion.
- Sort & validate TSI key value insertion.
- Handle nil MeasurementIterator.
- Add long-line support to client importer.
- Update to go 1.9.2.
- InfluxDB now uses MIT licensed version of BurntSushi/toml.
Bug fixes
- Change the default stats interval to 1 second instead of 10 seconds.
- illumos build broken on .
- Prevent privileges on non-existent databases from being set.
- tool now separates out logging to and . Thanks @xginn8!
- Dropping measurement used several GB disk space.
- Fix the CQ start and end times to use Unix timestamps.
- CLI case-sensitivity.
- Fixed time boundaries for continuous queries with time zones.
- Return query parsing errors in CSV formats.
- Fix time zone shifts when the shift happens on a time zone boundary.
- Parse time literals using the time zone in the statement.
- Reduce CPU usage when checking series cardinality
- Fix backups when snapshot is empty.
- Cursor leak, resulting in an accumulation of files after compactions.
- Improve condition parsing.
- Ensure inputs are closed on error. Add runtime GC finalizer as additional guard to close iterators.
- Fix merging bug on system iterators.
- Force subqueries to match the parent queries ordering.
- Fix race condition accessing map.
- Fix deadlock when calling .
- Fix so it skips missing files.
- Reduce how long it takes to walk the varrefs in an expression.
- Address .
- Drop Series Cause Write Fail/Write Timeouts/High Memory Usage.
- Fix increased memory usage in cache and wal readers.
- An OSS read-only user should be able to list measurements on a database.
- Ensure time and tag-based condition can be used with tsi1 index when deleting.
- Prevent deadlock when doing math on the result of a subquery.
- Fix a minor memory leak in batching points in TSDB.
- Don’t assume is present in package post-install script.
- Fix missing man pages in new packaging output.
- Fix use of in service file.
- Fix WAL panic: runtime error: makeslice: cap out of range.
- Copy returned bytes from TSI meta functions.
- Fix data deleted outside of time range.
- Fix data dropped incorrectly during compaction.
- Prevent deadlock during Collectd, Graphite, openTSDB, and UDP shutdown.
- Remove the pidfile after the server has exited.
- Return for successful read on .
- Fix race inside Measurement index.
- Ensure retention service always removes local shards.
- Handle utf16 files when reading the configuration file.
- Fix .
1.3.7 [2017-10-26]
Release Notes
Bug fix identified via Community and InfluxCloud. The build artifacts are now consistent with v1.3.5.
Bug fixes
- Don’t assume is present in package post-install script.
- Fix use of in service file.
- Fix missing man pages in new packaging output.
- Add RPM dependency on shadow-utils for .
- Fix data deleted outside of specified time range when using
- Fix data dropped incorrectly during compaction.
- Return for a successful read on .
- Copy returned bytes from TSI meta functions.
v1.3.6 [2017-09-28]
Release Notes
Bug fix identified via Community and InfluxCloud.
Bug fixes
- Reduce how long it takes to walk the varrefs in an expression.
- Address .
- Fix increased memory usage in cache and WAL readers for clusters with a large number of shards.
- Prevent deadlock when doing math on the result of a subquery.
- Fix several race conditions present in the shard and storage engine.
- Fix race condition on cache entry.
Release Notes
Bug fix identified via Community and InfluxCloud.
Bug fixes
- Fix race condition accessing map.
- Fix deadlock when calling .
v1.3.5 [2017-08-29]
Release Notes
Bug fix identified via Community and InfluxCloud.
Bug fixes
- Fix race condition accessing map.
- Fix deadlock when calling .
v1.3.4 [2017-08-23]
Release Notes
Bug fix identified via Community and InfluxCloud.
Bug fixes
- Fixed time boundaries for continuous queries with time zones.
- Fix time zone shifts when the shift happens on a time zone boundary.
- Parse time literals using the time zone in the select statement.
- Fix drop measurement not dropping all data.
- Fix backups when snapshot is empty.
- Eliminated cursor leak, resulting in an accumulation of .tsm.tmp files after compactions.
- Fix Deadlock when dropping measurement and writing.
- Ensure inputs are closed on error. Add runtime GC finalizer as additional guard to close iterators.
- Fix leaking tmp file when large compaction aborted.
v1.3.3 [2017-08-10]
Release Notes
Bug fix identified via Community and InfluxCloud.
Bug fixes
- Resolves a memory leak when NewReaderIterator creates a nilFloatIterator, the reader is not closed.
v1.3.2 [2017-08-04]
Release Notes
Minor bug fixes were identified via Community and InfluxCloud.
Bug fixes
- Interrupt “in-progress” TSM compactions.
- Prevent excessive memory usage when dropping series.
- Significantly improve performance of SHOW TAG VALUES.
v1.3.1 [2017-07-20]
Release Notes
Minor bug fixes were identified via Community and InfluxCloud.
Bug fixes
- Ensure temporary TSM files get cleaned up when compaction aborted.
- Address deadlock issue causing 1.3.0 to become unresponsive.
- Duplicate points generated via INSERT after DELETE.
- Fix the CQ start and end times to use Unix timestamps.
v1.3.0 [2017-06-21]
Release Notes
TSI
Version 1.3.0 marks the first official release of the new InfluxDB time series index (TSI) engine.
The TSI engine is a significant technical advancement in InfluxDB. It offers a solution to the time-structured merge tree engine’s high series cardinality issue. With TSI, the number of series should be unbounded by the memory on the server hardware and the number of existing series will have a negligible impact on database startup time. See Paul Dix’s blogpost Path to 1 Billion Time Series: InfluxDB High Cardinality Indexing Ready for Testing for additional information.
TSI is disabled by default in version 1.3. To enable TSI, uncomment the setting and set it to . The setting is in the section of the configuration file. Next, restart your InfluxDB instance.
Continuous Query Statistics
When enabled, each time a continuous query is completed, a number of details regarding the execution are written to the measurement of the internal monitor database ( by default). The tags and fields of interest are
| tag / field | description |
|---|---|
| name of database | |
| name of continuous query | |
| query execution time in nanoseconds | |
| lower bound of time range | |
| upper bound of time range | |
| number of points written to the target measurement |
- and are UNIX timestamps, in nanoseconds.
- The number of points written is also included in CQ log messages.
Removals
The admin UI is removed and unusable in this release. The configuration section will be ignored.
Configuration Changes
- The top-level config now defaults to . The previous default was just , causing the backup and restore port to be bound on all available interfaces (i.e. including interfaces on the public internet).
The following new configuration options are available.
Section
- was added with a default of 25,000,000, but can be disabled by setting it to 0. Specifies the maximum size (in bytes) of a client request body. When a client sends data that exceeds the configured maximum size, a HTTP response is returned.
Section
- was added with a default of . When set to , continuous query execution statistics are written to the default monitor store.
Features
- Add WAL sync delay
- Add chunked request processing back into the Go client v2
- Allow non-admin users to execute SHOW DATABASES
- Reduce memory allocations by reusing gzip.Writers across requests
- Add system information to /debug/vars
- Add modulo operator to the query language.
- Failed points during an import now result in a non-zero exit code
- Expose some configuration settings via SHOW DIAGNOSTICS
- Support single and multiline comments in InfluxQL
- Support timezone offsets for queries
- Add “integral” function to InfluxQL
- Add “non_negative_difference” function to InfluxQL
- Add bitwise AND, OR and XOR operators to the query language
- Write throughput/concurrency improvements
- Remove the admin UI
- Update to go1.8.1
- Add max concurrent compaction limits
- Add TSI support tooling
- Track HTTP client requests for /write and /query with /debug/requests
- Write and compaction stability
- Add new profile endpoint for gathering all debug profiles and queries in single archive
- Add nanosecond duration literal support
- Optimize top() and bottom() using an incremental aggregator
- Maintain the tags of points selected by top() or bottom() when writing the results.
- Write CQ stats to the database
Bugfixes
- Several statements were missing the DefaultDatabase method
- Fix spelling mistake in HTTP section of config -- shared-secret
- History file should redact passwords before saving to history
- Suppress headers in output for influx cli when they are the same
- Add chunked/chunk size as setting/options in cli
- Do not increment the continuous query statistic if no query is run
- Forbid wildcards in binary expressions
- Fix fill(linear) when multiple series exist and there are null values
- Update liner dependency to handle docker exec
- Bind backup and restore port to localhost by default
- Kill query not killing query
- KILL QUERY should work during all phases of a query
- Simplify admin user check.
- Significantly improve DROP DATABASE speed
- Return an error when an invalid duration literal is parsed
- Fix the time range when an exact timestamp is selected
- Fix query parser when using addition and subtraction without spaces
- Fix a regression when math was used with selectors
- Ensure the input for certain functions in the query engine are ordered
- Significantly improve shutdown speed for high cardinality databases
- Fix racy integration test
- Prevent overflowing or underflowing during window computation
- Enabled golint for admin, httpd, subscriber, udp, thanks @karlding
- Implicitly cast null to false in binary expressions with a Boolean
- Restrict fill(none) and fill(linear) to be usable only with aggregate queries
- Restrict top() and bottom() selectors to be used with no other functions
- top() and bottom() now returns the time for every point
- Remove default upper time bound on DELETE queries
- Fix LIMIT and OFFSET for certain aggregate queries
- Refactor the subquery code and fix outer condition queries
- Fix compaction aborted log messages
- TSM compaction does not remove .tmp on error
- Set the CSV output to an empty string for null values
- Compaction exhausting disk resources in InfluxDB
- Small edits to the etc/config.sample.toml file
- Points beyond retention policy scope are dropped silently
- Fix TSM tmp file leaked on disk
- Fix large field keys preventing snapshot compactions
- URL query parameter credentials take priority over Authentication header
- TSI branch has duplicate tag values
- Out of memory when using HTTP API
- Check file count before attempting a TSI level compaction.
- index file fd leak in tsi branch
- Fix TSI non-contiguous compaction panic
v1.2.4 [2017-05-08]
Bugfixes
- Prefix partial write errors with to generalize identification in other subsystems.
v1.2.3 [2017-04-17]
Bugfixes
- Redact passwords before saving them to the history file.
- Add the missing DefaultDatabase method to several InfluxQL statements.
- Fix segment violation in models.Tags.Get.
- Simplify the admin user check.
- Fix a regression when math was used with selectors.
- Ensure the input for certain functions in the query engine are ordered.
- Fix issue where deleted field keys created unparseable points.
v1.2.2 [2017-03-14]
Release Notes
Configuration Changes
Section
- now defaults to . In versions 1.0 and 1.1, the default setting was , but due to a bug, the value in use in versions 1.0 and 1.1 was effectively . In versions 1.2.0 through 1.2.1, we fixed that bug, but the fix caused a breaking change for Grafana and Kapacitor users; users who had not set to experienced truncated/partial data due to the row limit. In version 1.2.2, we’ve changed the default setting to to match the behavior in versions 1.0 and 1.1.
Bug fixes
- Change the default setting from to to prevent the absence of data in Grafana or Kapacitor.
v1.2.1 [2017-03-08]
Release Notes
Bugfixes
- Treat non-reserved measurement names with underscores as normal measurements.
- Reduce the expression in a subquery to avoid a panic.
- Properly select a tag within a subquery.
- Prevent a panic when aggregates are used in an inner query with a raw query.
- Points missing after compaction.
- Point.UnmarshalBinary() bounds check.
- Interface conversion: tsm1.Value is tsm1.IntegerValue, not tsm1.FloatValue.
- Map types correctly when using a regex and one of the measurements is empty.
- Map types correctly when selecting a field with multiple measurements where one of the measurements is empty.
- Include IsRawQuery in the rewritten statement for meta queries.
- Fix race in WALEntry.Encode and Values.Deduplicate
- Fix panic in collectd when configured to read types DB from directory.
- Fix ORDER BY time DESC with ordering series keys.
- Fix mapping of types when the measurement uses a regular expression.
- Fix LIMIT and OFFSET when they are used in a subquery.
- Fix incorrect math when aggregates that emit different times are used.
- Fix EvalType when a parenthesis expression is used.
- Fix authentication when subqueries are present.
- Expand query dimensions from the subquery.
- Dividing aggregate functions with different outputs doesn’t panic.
- Anchors not working as expected with case-insensitive regular expression.
v1.2.0 [2017-01-24]
Release Notes
This release introduces a major new querying capability in the form of sub-queries, and provides several performance improvements, including a 50% or better gain in write performance on larger numbers of cores. The release adds some stability and memory-related improvements, as well as several CLI-related bug fixes. If upgrading from a prior version, please read the configuration changes in the following section before upgrading.
Configuration Changes
The following new configuration options are available, if upgrading to from prior versions.
Section
- which defaults to . This field also accepts and and enables different levels of transmission security for the collectd plugin.
- which defaults to . Specifies where to locate the authentication file used to authenticate clients when using signed or encrypted mode.
Deprecations
The stress tool will be removed in a subsequent release. We recommend using as a replacement.
Features
- Remove the override of GOMAXPROCS.
- Uncomment section headers from the default configuration file.
- Improve write performance significantly.
- Prune data in meta store for deleted shards.
- Update latest dependencies with Godeps.
- Introduce syntax for marking a partial response with chunking.
- Use X-Forwarded-For IP address in HTTP logger if present.
- Add support for secure transmission via collectd.
- Switch logging to use structured logging everywhere.
- [CLI feature request] USE retention policy for queries.
- Add clear command to CLI.
- Adding ability to use parameters in queries in the v2 client using the map in the struct.
- Allow add items to array config via ENV.
- Support subquery execution in the query language.
- Verbose output for SSL connection errors.
- Cache snapshotting performance improvements
Bugfixes
- Fix potential race condition in correctness of tsm1_cache memBytes statistic.
- Fix broken error return on meta client’s UpdateUser and DropContinuousQuery methods.
- Fix string quoting and significantly improve performance of .
- CLI was caching db/rp for insert into statements.
- Fix CLI import bug when using self-signed SSL certificates.
- Fix cross-platform backup/restore.
- Ensures that all user privileges associated with a database are removed when the database is dropped.
- Return the time from a percentile call on an integer.
- Expand string and Boolean fields when using a wildcard with .
- Fix chuid argument order in init script.
- Reject invalid subscription URLs.
- CLI should use spaces for alignment, not tabs.
- 0.12.2 InfluxDB CLI client PRECISION returns “Unknown precision…”.
- Fix parse key panic when missing tag value.
- Rentention Policy should not allow or as a shard duration.
- Return Error instead of panic when decoding point values.
- Fix slice out of bounds panic when pruning shard groups.
- Drop database will delete /influxdb/data directory.
- Ensure Subscriber service can be disabled.
- Fix race in storage engine.
- InfluxDB should do a partial write on mismatched type errors.
v1.1.5 [2017-05-08]
Bugfixes
- Redact passwords before saving them to the history file.
- Add the missing DefaultDatabase method to several InfluxQL statements.
v1.1.4 [2017-02-27]
Bugfixes
- Backport from 1.2.0: Reduce GC allocations.
v1.1.3 [2017-02-17]
Bugfixes
- Remove Tags.shouldCopy, replace with forceCopy on series creation.
v1.1.2 [2017-02-16]
Bugfixes
- Fix memory leak when writing new series over HTTP.
- Fix series tag iteration segfault.
- Fix tag dereferencing panic.
v1.1.1 [2016-12-06]
Features
- Update Go version to 1.7.4.
Bugfixes
- Fix string fields w/ trailing slashes.
- Quote the empty string as an ident.
- Fix incorrect tag value in error message.
Security
Go 1.7.4 was released to address two security issues. This release includes these security fixes.
v1.1.0 [2016-11-14]
Release Notes
This release is built with GoLang 1.7.3 and provides many performance optimizations, stability changes and a few new query capabilities. If upgrading from a prior version, please read the configuration changes below section before upgrading.
Deprecations
The admin interface is deprecated and will be removed in a subsequent release. The configuration setting to enable the admin UI is now disabled by default, but can be enabled if necessary. We recommend using Chronograf or Grafana as a replacement.
Configuration Changes
The following configuration changes may need to changed before upgrading to from prior versions.
Section
- now default to false. If you are currently using the admin interaface, you will need to change this value to to re-enable it. The admin interface is currently deprecated and will be removed in a subsequent release.
Section
- was added with a default of 100,000, but can be disabled by setting it to . Existing measurements with tags that exceed this limit will continue to load, but writes that would cause the tags cardinality to increase will be dropped and a error will be returned to the caller. This limit can be used to prevent high cardinality tag values from being written to a measurement.
- has been increased to from to . This setting is the maximum amount of RAM, in bytes, a shard cache can use before it rejects writes with an error. Setting this value to disables the limit.
- has been decreased from to . This setting determines how long values will stay in the shard cache while the shard is cold for writes.
- has been decreased from to . The shorter duration allows cold shards to be compacted to an optimal state more quickly.
Features
The query language has been extended with a few new features:
- Support regular expressions on fields keys in select clause.
- New fill option.
- New function.
- Support for commands.
All Changes:
- Filter out series within shards that do not have data for that series.
- Rewrite regular expressions of the form host = /^server-a$/ to host = ‘server-a’, to take advantage of the tsdb index.
- Improve compaction planning performance by caching tsm file stats.
- Align binary math expression streams by time.
- Reduce map allocations when computing the TagSet of a measurement.
- Make input plugin services open/close idempotent.
- Speed up shutdown by closing shards concurrently.
- Add sample function to query language.
- Add to query language.
- Implement cumulative_sum() function.
- Update defaults in config for latest best practices.
- UDP Client: Split large points.
- Add stats for active compactions, compaction errors.
- More man pages for the other tools we package and compress man pages fully.
- Add max-values-per-tag to limit high tag cardinality data.
- Update jwt-go dependency to version 3.
- Support enable HTTP service over unix domain socket.
- Add additional statistics to query executor.
- Feature request: should dump WAL files.
- Implement text/csv content encoding for the response writer.
- Support tools for running async queries.
- Support ON and use default database for SHOW commands.
- Correctly read in input from a non-interactive stream for the CLI.
- Support and for setting username/password in the CLI.
- Optimize first/last when no group by interval is present.
- Make regular expressions work on field and dimension keys in SELECT clause.
- Change default time boundaries for raw queries.
- Support mixed duration units.
Bugfixes
- Avoid deadlock when is hit.
- Fix incorrect grouping when multiple aggregates are used with sparse data.
- Fix output duration units for SHOW QUERIES.
- Truncate the version string when linking to the documentation.
- influx_inspect: export does not escape field keys.
- Fix issue where point would be written to wrong shard.
- Fix retention policy inconsistencies.
- Remove accidentally added string support for the stddev call.
- Remove /data/process_continuous_queries endpoint.
- Enable https subscriptions to work with custom CA certificates.
- Reduce query planning allocations.
- Shard stats include WAL path tag so disk bytes make more sense.
- Panic with unread show series iterators during drop database.
- Use consistent column output from the CLI for column formatted responses.
- Correctly use password-type field in Admin UI.
- Duplicate parsing bug in ALTER RETENTION POLICY.
- Fix database locked up when deleting shards.
- Fix mmap dereferencing.
- Fix base64 encoding issue with /debug/vars stats.
- Drop measurement causes cache max memory exceeded error.
- Decrement number of measurements only once when deleting the last series from a measurement.
- Delete statement returns an error when retention policy or database is specified.
- Fix the dollar sign so it properly handles reserved keywords.
- Exceeding max retention policy duration gives incorrect error message.
- Drop time when used as a tag or field key.
v1.0.2 [2016-10-05]
Bugfixes
- Fix RLE integer decoding producing negative numbers.
- Avoid stat syscall when planning compactions.
- Subscription data loss under high write load.
- Do not automatically reset the shard duration when using ALTER RETENTION POLICY.
- Ensure correct shard groups created when retention policy has been altered.
v1.0.1 [2016-09-26]
Bugfixes
- Prevent users from manually using system queries since incorrect use would result in a panic.
- Ensure fieldsCreated stat available in shard measurement.
- Report cmdline and memstats in /debug/vars.
- Fixing typo within example configuration file.
- Implement time math for lazy time literals.
- Fix database locked up when deleting shards.
- Skip past points at the same time in derivative call within a merged series.
- Read an invalid JSON response as an error in the Influx client.
v1.0.0 [2016-09-08]
Release Notes
Inital release of InfluxDB.
Breaking changes
- was added with a default of 1M but can be disabled by setting it to . Existing databases with series that exceed this limit will continue to load but writes that would create new series will fail.
- Config option has been replaced with .
- Support for config options and has been removed; use and instead.
- Config option within the section, has been renamed to , and defaults to .
- The keywords , , and where removed for this release. This means you no longer need to specify for or for . If these are specified, a query parse error is returned.
- The Shard stat has been renamed to for consistency with other stats.
With this release the systemd configuration files for InfluxDB will use the system configured default for logging and will no longer write files to by default. On most systems, the logs will be directed to the systemd journal and can be accessed by . Consult the systemd journald documentation for configuring journald.
Features
- Add mode function.
- Support negative timestamps for the query engine.
- Write path stats.
- Add MaxSeriesPerDatabase config setting.
- Remove IF EXISTS/IF NOT EXISTS from influxql language.
- Update go package library dependencies.
- Add tsm file export to influx_inspect tool.
- Create man pages for commands.
- Return 403 Forbidden when authentication succeeds but authorization fails.
- Added favicon.
- Run continuous query for multiple buckets rather than one per bucket.
- Log the CQ execution time when continuous query logging is enabled.
- Trim BOM from Windows Notepad-saved config files.
- Update help and remove unused config options from the configuration file.
- Add NodeID to execution options.
- Make httpd logger closer to Common (& combined) Log Format.
- Allow any variant of the help option to trigger the help.
- Reduce allocations during query parsing.
- Optimize timestamp run-length decoding.
- Adds monitoring statistic for on-disk shard size.
- Add HTTP(s) based subscriptions.
- Add new HTTP statistics to monitoring.
- Speed up drop database.
- Add Holt-Winter forecasting function.
- Add support for JWT token authentication.
- Add ability to create snapshots of shards.
- Parallelize iterators.
- Teach the http service how to enforce connection limits.
- Support cast syntax for selecting a specific type.
- Refactor monitor service to avoid expvar and write monitor statistics on a truncated time interval.
- Dynamically update the documentation link in the admin UI.
- Support wildcards in aggregate functions.
- Support specifying a retention policy for the graphite service.
- Add extra trace logging to tsm engine.
- Add stats and diagnostics to the TSM engine.
- Support regex selection in SHOW TAG VALUES for the key.
- Modify the default retention policy name and make it configurable.
- Update SHOW FIELD KEYS to return the field type with the field key.
- Support bound parameters in the parser.
- Add https-private-key option to httpd config.
- Support loading a folder for collectd typesdb files.
Bugfixes
- Optimize queries that compare a tag value to an empty string.
- Allow blank lines in the line protocol input.
- Runtime: goroutine stack exceeds 1000000000-byte limit.
- Fix alter retention policy when all options are used.
- Concurrent series limit.
- Ensure gzip writer is closed in influx_inspect export.
- Fix CREATE DATABASE when dealing with default values.
- Fix UDP pointsRx being incremented twice.
- Tombstone memory improvements.
- Hardcode auto generated RP names to autogen.
- Ensure IDs can’t clash when managing Continuous Queries.
- Continuous full compactions.
- Remove limiter from walkShards.
- Copy tags in influx_stress to avoid a concurrent write panic on a map.
- Do not run continuous queries that have no time span.
- Move the CQ interval by the group by offset.
- Fix panic parsing empty key.
- Update connection settings when changing hosts in CLI.
- Always use the demo config when outputting a new config.
- Minor improvements to init script. Removes sysvinit-utils as package dependency.
- Fix compaction planning with large TSM files.
- Duplicate data for the same timestamp.
- Fix panic: truncate the slice when merging the caches.
- Fix regex binary encoding for a measurement.
- Fix fill(previous) when used with math operators.
- Rename dumptsmdev to dumptsm in influx_inspect.
- Remove a double lock in the tsm1 index writer.
- Remove FieldCodec from TSDB package.
- Allow a non-admin to call “use” for the influx CLI.
- Set the condition cursor instead of aux iterator when creating a nil condition cursor.
- Update to work with clusters, ssl, and username/password auth. Code cleanup.
- Modify the max nanosecond time to be one nanosecond less.
- Include sysvinit-tools as an rpm dependency.
- Add port to all graphite log output to help with debugging multiple endpoints.
- Fix panic: runtime error: index out of range.
- Remove systemd output redirection.
- Database unresponsive after DROP MEASUREMENT.
- Address Out of Memory Error when Dropping Measurement.
- Fix the point validation parser to identify and sort tags correctly.
- Prevent panic in concurrent auth cache write.
- Set X-Influxdb-Version header on every request (even 404 requests).
- Prevent panic if there are no values.
- Time sorting broken with overwritten points.
- queries with strings that look like dates end up with date types, not string types.
- Concurrent map read write panic.
- Drop writes from before the retention policy time window.
- Fix SELECT statement required privileges.
- Filter out sources that do not match the shard database/retention policy.
- Truncate the shard group end time if it exceeds MaxNanoTime.
- Batch SELECT INTO / CQ writes.
- Fix compaction planning re-compacting large TSM files.
- Ensure client sends correct precision when inserting points.
- Accept points with trailing whitespace.
- Fix panic in SHOW FIELD KEYS.
- Disable limit optimization when using an aggregate.
- Fix panic: interface conversion: tsm1.Value is *tsm1.StringValue, not *tsm1.FloatValue.
- Data race when dropping a database immediately after writing to it.
- Make sure admin exists before authenticating query.
- Print the query executor’s stack trace on a panic to the log.
- Fix read tombstones: EOF.
- Query-log-enabled in config not ignored anymore.
- Ensure clients requesting gzip encoded bodies don’t receive empty body.
- Optimize shard loading.
- Queries slow down hundreds times after overwriting points.
- SHOW TAG VALUES accepts != and !~ in WHERE clause.
- Remove old cluster code.
- Ensure that future points considered in SHOW queries.
- Fix full compactions conflicting with level compactions.
- Overwriting points on large series can cause memory spikes during compactions.
- Fix parseFill to check for fill ident before attempting to parse an expression.
- Max index entries exceeded.
- Address slow startup time.
- Fix measurement field panic in tsm1 engine.
- Queries against files that have just been compacted need to point to new files.
- Check that retention policies exist before creating CQ.
What’s New in the Share the Memories v1.0.2 serial key or number?
Screen Shot
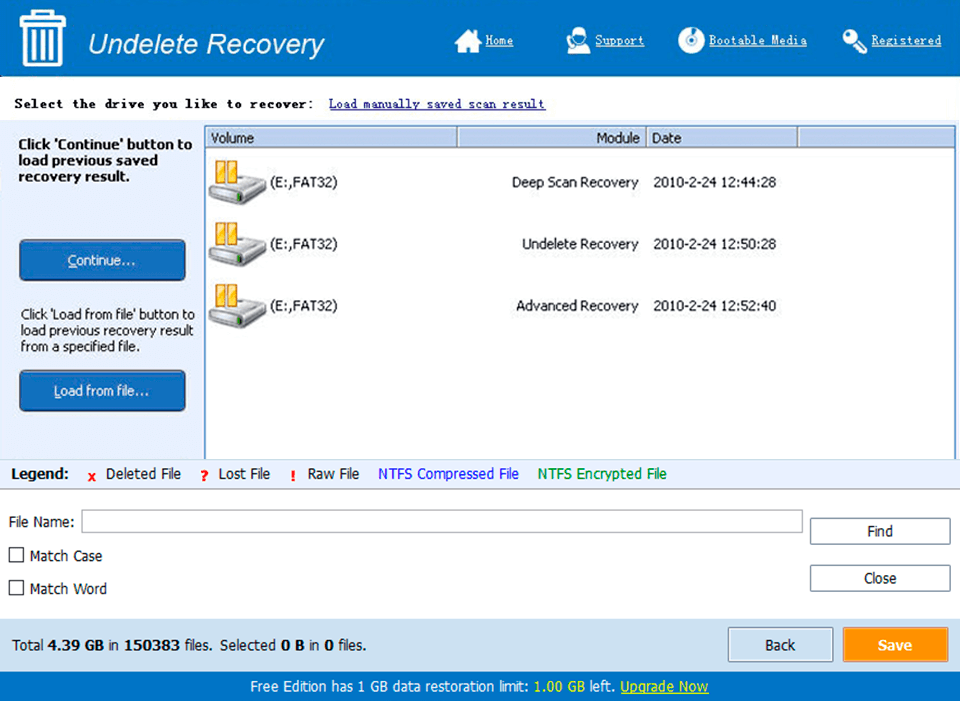
System Requirements for Share the Memories v1.0.2 serial key or number
- First, download the Share the Memories v1.0.2 serial key or number
-
You can download its setup from given links:

Share the Memories v1.0.2 serial key or number & PC Free Download

Share the Memories v1.0.2 serial key or number& Free Download
