
Poker Analyzer 1.2 serial key or number

Poker Analyzer 1.2 serial key or number
Security and Game Integrity
The measures that we take to safeguard our players combined with the security we build into our games make The Stars Group brands among the most trusted in the industry. Millions of players choose us because we provide the very best online experience available in a fair and honest environment. This is a real passion for everyone at The Stars Group.
All our games and the technology that supports them are regularly and independently assessed by the most robust international gaming regulators in the world, and are backed by our team of more than 300 Security and Game Integrity professionals. These teams use proprietary fraud management systems 24 hours a day seven days a week to prevent malicious activity, track game play and reduce financial risk.
Security Highlights
Software download
Ensuring that our desktop software is downloaded in its intended and unmodified form is the first critical step in protecting the integrity of our games. The installer executable file is signed using an RSA 2048-bit code-signing certificate that was issued to The Stars Group by VeriSign. This is a public certificate authority, which can be validated using your web-browser and ensures that the desktop client came from the software publisher. It protects the desktop client installer from alteration between the point of publication and later installation on your machine.
Registration, Verification and Validation
The registration process is central to preventing players who are not of legal age from being able to participate in any real-money activity on any of our products. It is also the first opportunity to identify any intent to abuse our systems. Players are required to be over the applicable legal age to play real-money games in their respective jurisdiction. The exact requirements for how a player completes account validation varies by license and market. The Stars Group strives to maintain full compliance in every jurisdiction.
AML and Fraud
The Stars Group employs stringent rules, alerts and limits to review and reduce risks of fraud, money laundering or terrorist financing, making money-laundering very hard to achieve. These include game protocols and screening processes at onboarding, KYC processes and rigorous analysis of fund movement. All real-money players across the group are screened within 24-hours of registration using World Check to ensure we have no player on a global sanction or terrorist watch-list.
Transaction Analysis
Every one of the millions of daily transactions that occur on our platforms is parsed through our Global Security systems. Those that are flagged based on pre-formulated rulesets are manually reviewed by dedicated investigators. Those rules draw upon the attributes of the individual transaction as well as past transactions, account history, technical account attributes, player profile and behavior.
Play Screening
The Security teams use other in-house rule engines that analyze the movement of funds, post-deposit, to search for inconsistencies with normal playing patterns. This analysis will consider possible chip dumping, bonus abuse, compromised accounts, big winners and losers, and other items to maintain the integrity of our platforms and games. The source of funds for all transactions is also reviewed to protect potentially vulnerable players. Protecting our players is always a key objective for us.
PROHIBITION ON ACCOUNT SHARING
Account Sharing, or multi-accounting, is a form of cheating where a player uses more than one account to deceive other players either to gain an anonymity advantage, misuse the Late Registration feature in tournaments or bypass restrictions placed on accounts. This is unique to online gaming and something we counter using state-of-the-art tools and detection methods. These protect honest players and safeguard the integrity of our platforms without compromising the player experience.
Third Party Tool Policy
We have an in-depth policy designed to clearly outline our rules pertaining to third-party tools as well as set a balance between fairness, enforceability and clarity. We created these rules in consultation with players, staff and software developers, and they have been adapted over time to suit the changing gaming and software environments. If a tool is detected on our system, we will typically seek to first educate and warn players against its use. In rare cases, if players persist, we may go as far as banning them and confiscating their funds for redistribution to victims of unfair play, as is permitted under our terms of service.
Collusion
Collusion is a form of cheating in which two or more players signal their holdings or otherwise form a partnership to the detriment of other players within a game. Every single hand dealt on PokerStars is recorded and can be examined after play using our sophisticated detection methods that run 24/7. Every unusual play pattern and player report is thoroughly and manually investigated by our expert security personnel. If any player is found to be colluding with others, his or her account may be permanently closed and funds redistributed to affected players.
Bot Prevention
We take pride in ensuring that the brains behind an account belong to a human and not a computer, analyzing every one of our accounts in three main areas: interaction with our software, detection of computer set-ups, and the way our players play poker. We also cross reference our database of billions of hands to determine how individual accounts play in comparison to known bot profiles. Every potential risk is investigated. Flagged accounts are quarantined and subjected to a series of sophisticated Turing tests to ensure a safe and level playing field for every player.
Play-time security
Our desktop client software uses the certificates issued by our own Certificate Authority (CA) to authenticate our servers. Our desktop client software uses the industry standard TLS 1.2 protocol. We are currently using a 2048-bit RSA key, which according to RSA is sufficient until 2030. We support the following ciphers: AES128-GCM-SHA256 (128bit). No private data, such as pocket cards, is ever transferred to other players except in accordance with the game rules and all client input is validated server-side.
Shuffling the deck
A fair and unpredictable shuffle algorithm is critical to our software. Two independent hardware sources of truly random data work together to keep our poker games fair.
- Quantis: a true hardware random number generator developed by Swiss-based company ID Quantique, which uses quantum randomness as an entropy source.
- User input: thousands of random variables generated by human interaction with our desktop client software, including mouse-movement and events timing.
Our Random Number Generator has successfully been tested to generally-accepted industry standards for highly-regulated jurisdictions by Gaming Laboratories International. Click here to read the Certification of Integrity. To read more about the PokerStars shuffle and Random Number Generator here.
Data may come from a population or from a sample. Small letters like x or y generally are used to represent data values. Most data can be put into the following categories:
| Quantitative Data | Qualitative Data | |
| Definition | Quantitative data are the result of counting or measuring attributes of a population. | Qualitative data are the result of categorizing or describing attributes of a population. |
| Data that you will see | Quantitative data are always numbers. | Qualitative data are generally described by words or letters. |
| Examples | Amount of money you have Height Weight Number of people living in your town Number of students who take statistics | Hair color Blood type Ethnic group The car a person drives The street a person lives on |
Researchers often prefer to use quantitative data over qualitative data because it lends itself more easily to mathematical analysis. For example, it does not make sense to find an average hair color or blood type.
Quantitative data may be either discrete or continuous.
All data that are the result of counting are called quantitative discrete data. These data take on only certain numerical values. If you count the number of phone calls you receive for each day of the week, you might get values such as zero, one, two, or three.
All data that are the result of measuring are quantitative continuous data assuming that we can measure accurately. Measuring angles in radians might result in such numbers as [latex]\displaystyle\frac{pi}{{6}},\frac{pi}{{3}},\frac{pi}{{2}},pi,\frac{{{3}pi}}{{4}}[/latex] , and so on. If you and your friends carry backpacks with books in them to school, the numbers of books in the backpacks are discrete data and the weights of the backpacks are continuous data.
Example of Quantitative Discrete Data
The data are the number of books students carry in their backpacks. You sample five students. Two students carry three books, one student carries four books, one student carries two books, and one student carries one book. The numbers of books (three, four, two, and one) are the quantitative discrete data.
Try It
The data are the number of machines in a gym. You sample five gyms. One gym has 12 machines, one gym has 15 machines, one gym has ten machines, one gym has 22 machines, and the other gym has 20 machines. What type of data is this?
Example of Quantitative Continuous Data
The data are the weights of backpacks with books in them. You sample the same five students. The weights (in pounds) of their backpacks are 6.2, 7, 6.8, 9.1, 4.3. Notice that backpacks carrying three books can have different weights. Weights are quantitative continuous data because weights are measured.
Try It
The data are the areas of lawns in square feet. You sample five houses. The areas of the lawns are 144 sq. feet, 160 sq. feet, 190 sq. feet, 180 sq. feet, and 210 sq. feet. What type of data is this?
Try It
A statistics professor collects information about the classification of her students as freshmen, sophomores, juniors, or seniors. The data she collects are summarized in the pie chart.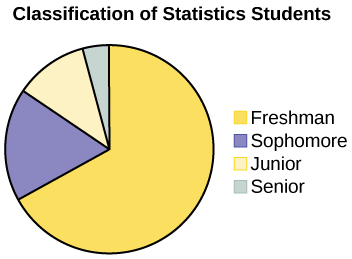 What type of data does this graph show?
What type of data does this graph show?
Example 1
Determine the correct data type (quantitative or qualitative). Indicate whether quantitative data are continuous or discrete. Hint: Data that are discrete often start with the words “the number of.”
- The number of pairs of shoes you own
- The type of car you drive
- The place where you go on vacation
- The distance it is from your home to the nearest grocery store
- The number of classes you take per school year.
- The tuition for your classes
- The type of calculator you use
- Movie ratings
- Political party preferences
- Weights of sumo wrestlers
- Amount of money (in dollars) won playing poker
- Number of correct answers on a quiz
- Peoples’ attitudes toward the government
- IQ scores
Omitting Categories and Missing Data
The table displays Ethnicity of Students but is missing the “Other/Unknown” category. This category contains people who did not feel they fit into any of the ethnicity categories or declined to respond. Notice that the frequencies do not add up to the total number of students. In this situation, create a bar graph and not a pie chart.
| Frequency | Percent | |
|---|---|---|
| Asian | 8,794 | 36.1% |
| Black | 1,412 | 5.8% |
| Filipino | 1,298 | 5.3% |
| Hispanic | 4,180 | 17.1% |
| Native American | 146 | 0.6% |
| Pacific Islander | 236 | 1.0% |
| White | 5,978 | 24.5% |
| TOTAL | 22,044 out of 24,382 | 90.4% out of 100% |
Figure 1. Ethnicity of Students

The following graph is the same as the previous graph but the “Other/Unknown” percent (9.6%) has been included. The “Other/Unknown” category is large compared to some of the other categories (Native American, 0.6%, Pacific Islander 1.0%). This is important to know when we think about what the data are telling us.
This particular bar graph in Figure 2 can be difficult to understand visually.
Figure 2. Bar Graph with Other/Unknown Category

The graph in Figure 3 is a Pareto chart. The Pareto chart has the bars sorted from largest to smallest and is easier to read and interpret.

Figure 3. Pareto Chart with Bars Sorted by Size
Источник: [https://torrent-igruha.org/3551-portal.html]
1.2: Definitions of Statistics, Probability, and Key Terms
- Last updated
- Save as PDF
- Page ID
- 704
The science of statistics deals with the collection, analysis, interpretation, and presentation of data. We see and use data in our everyday lives.
Collaborative Exercise
In your classroom, try this exercise. Have class members write down the average time (in hours, to the nearest half-hour) they sleep per night. Your instructor will record the data. Then create a simple graph (called a dot plot) of the data. A dot plot consists of a number line and dots (or points) positioned above the number line. For example, consider the following data:
5; 5.5; 6; 6; 6; 6.5; 6.5; 6.5; 6.5; 7; 7; 8; 8; 9
The dot plot for this data would be as follows:
- Does your dot plot look the same as or different from the example? Why?
- If you did the same example in an English class with the same number of students, do you think the results would be the same? Why or why not?
- Where do your data appear to cluster? How might you interpret the clustering?
The questions above ask you to analyze and interpret your data. With this example, you have begun your study of statistics.
In this course, you will learn how to organize and summarize data. Organizing and summarizing data is called descriptive statistics. Two ways to summarize data are by graphing and by using numbers (for example, finding an average). After you have studied probability and probability distributions, you will use formal methods for drawing conclusions from "good" data. The formal methods are called inferential statistics. Statistical inference uses probability to determine how confident we can be that our conclusions are correct.
Effective interpretation of data (inference) is based on good procedures for producing data and thoughtful examination of the data. You will encounter what will seem to be too many mathematical formulas for interpreting data. The goal of statistics is not to perform numerous calculations using the formulas, but to gain an understanding of your data. The calculations can be done using a calculator or a computer. The understanding must come from you. If you can thoroughly grasp the basics of statistics, you can be more confident in the decisions you make in life.
Probability
Probability is a mathematical tool used to study randomness. It deals with the chance (the likelihood) of an event occurring. For example, if you toss a fair coin four times, the outcomes may not be two heads and two tails. However, if you toss the same coin 4,000 times, the outcomes will be close to half heads and half tails. The expected theoretical probability of heads in any one toss is \(\frac{1}{2}\) or 0.5. Even though the outcomes of a few repetitions are uncertain, there is a regular pattern of outcomes when there are many repetitions. After reading about the English statistician Karl Pearson who tossed a coin 24,000 times with a result of 12,012 heads, one of the authors tossed a coin 2,000 times. The results were 996 heads. The fraction \(\frac{996}{2000}\) is equal to 0.498 which is very close to 0.5, the expected probability.
The theory of probability began with the study of games of chance such as poker. Predictions take the form of probabilities. To predict the likelihood of an earthquake, of rain, or whether you will get an A in this course, we use probabilities. Doctors use probability to determine the chance of a vaccination causing the disease the vaccination is supposed to prevent. A stockbroker uses probability to determine the rate of return on a client's investments. You might use probability to decide to buy a lottery ticket or not. In your study of statistics, you will use the power of mathematics through probability calculations to analyze and interpret your data.
Key Terms
In statistics, we generally want to study apopulation. You can think of a population as a collection of persons, things, or objects under study. To study the population, we select a sample. The idea of samplingis to select a portion (or subset) of the larger population and study that portion (the sample) to gain information about the population. Data are the result of sampling from a population.
Because it takes a lot of time and money to examine an entire population, sampling is a very practical technique. If you wished to compute the overall grade point average at your school, it would make sense to select a sample of students who attend the school. The data collected from the sample would be the students' grade point averages. In presidential elections, opinion poll samples of 1,000–2,000 people are taken. The opinion poll is supposed to represent the views of the people in the entire country. Manufacturers of canned carbonated drinks take samples to determine if a 16 ounce can contains 16 ounces of carbonated drink.
From the sample data, we can calculate a statistic. A statisticis a number that represents a property of the sample. For example, if we consider one math class to be a sample of the population of all math classes, then the average number of points earned by students in that one math class at the end of the term is an example of a statistic. The statistic is an estimate of a population parameter. A parameteris a number that is a property of the population. Since we considered all math classes to be the population, then the average number of points earned per student over all the math classes is an example of a parameter.
One of the main concerns in the field of statistics is how accurately a statistic estimates a parameter. The accuracy really depends on how well the sample represents the population. The sample must contain the characteristics of the population in order to be a representative sample. We are interested in both the sample statistic and the population parameter in inferential statistics. In a later chapter, we will use the sample statistic to test the validity of the established population parameter.
A variable, notated by capital letters such as \(X\) and \(Y\), is a characteristic of interest for each person or thing in a population. Variables may be numerical or categorical. Numerical variables take on values with equal units such as weight in pounds and time in hours. Categorical variables place the person or thing into a category. If we let \(X\) equal the number of points earned by one math student at the end of a term, then \(X\) is a numerical variable. If we let \(Y\) be a person's party affiliation, then some examples of \(Y\) include Republican, Democrat, and Independent. \(Y\) is a categorical variable. We could do some math with values of \(X\) (calculate the average number of points earned, for example), but it makes no sense to do math with values of \(Y\) (calculating an average party affiliation makes no sense).
Data are the actual values of the variable. They may be numbers or they may be words. Datum is a single value.
Two words that come up often in statistics are mean and proportion. If you were to take three exams in your math classes and obtain scores of 86, 75, and 92, you would calculate your mean score by adding the three exam scores and dividing by three (your mean score would be 84.3 to one decimal place). If, in your math class, there are 40 students and 22 are men and 18 are women, then the proportion of men students is \(\frac{22}{40}\) and the proportion of women students is \(\frac{18}{40}\). Mean and proportion are discussed in more detail in later chapters.
The words "mean" and "average" are often used interchangeably. The substitution of one word for the other is common practice. The technical term is "arithmetic mean," and "average" is technically a center location. However, in practice among non-statisticians, "average" is commonly accepted for "arithmetic mean."
Example \(\PageIndex{1}\)
Determine what the key terms refer to in the following study. We want to know the average (mean) amount of money first year college students spend at ABC College on school supplies that do not include books. We randomly survey 100 first year students at the college. Three of those students spent $150, $200, and $225, respectively.
Answer
- The population is all first year students attending ABC College this term.
- The sample could be all students enrolled in one section of a beginning statistics course at ABC College (although this sample may not represent the entire population).
- The parameter is the average (mean) amount of money spent (excluding books) by first year college students at ABC College this term.
- The statistic is the average (mean) amount of money spent (excluding books) by first year college students in the sample.
- The variable could be the amount of money spent (excluding books) by one first year student. Let \(X\) = the amount of money spent (excluding books) by one first year student attending ABC College.
- The data are the dollar amounts spent by the first year students. Examples of the data are $150, $200, and $225.
Exercise \(\PageIndex{1}\)
Determine what the key terms refer to in the following study. We want to know the average (mean) amount of money spent on school uniforms each year by families with children at Knoll Academy. We randomly survey 100 families with children in the school. Three of the families spent $65, $75, and $95, respectively.
Answer
- The population is all families with children attending Knoll Academy.
- The sample is a random selection of 100 families with children attending Knoll Academy.
- The parameter is the average (mean) amount of money spent on school uniforms by families with children at Knoll Academy.
- The statistic is the average (mean) amount of money spent on school uniforms by families in the sample.
- The variable is the amount of money spent by one family. Let \(X\) = the amount of money spent on school uniforms by one family with children attending Knoll Academy.
- The data are the dollar amounts spent by the families. Examples of the data are $65, $75, and $95.
Example \(\PageIndex{2}\)
Determine what the key terms refer to in the following study.
A study was conducted at a local college to analyze the average cumulative GPA’s of students who graduated last year. Fill in the letter of the phrase that best describes each of the items below.
1._____ Population 2._____ Statistic 3._____ Parameter 4._____ Sample 5._____ Variable 6._____ Data
- all students who attended the college last year
- the cumulative GPA of one student who graduated from the college last year
- 3.65, 2.80, 1.50, 3.90
- a group of students who graduated from the college last year, randomly selected
- the average cumulative GPA of students who graduated from the college last year
- all students who graduated from the college last year
- the average cumulative GPA of students in the study who graduated from the college last year
Answer
1. f; 2. g; 3. e; 4. d; 5. b; 6. c
Example \(\PageIndex{3}\)
Determine what the key terms refer to in the following study.
As part of a study designed to test the safety of automobiles, the National Transportation Safety Board collected and reviewed data about the effects of an automobile crash on test dummies. Here is the criterion they used:
| Speed at which Cars Crashed | Location of “drive” (i.e. dummies) |
| 35 miles/hour | Front Seat |
Cars with dummies in the front seats were crashed into a wall at a speed of 35 miles per hour. We want to know the proportion of dummies in the driver’s seat that would have had head injuries, if they had been actual drivers. We start with a simple random sample of 75 cars.
Answer
- The population is all cars containing dummies in the front seat.
- The sample is the 75 cars, selected by a simple random sample.
- The parameter is the proportion of driver dummies (if they had been real people) who would have suffered head injuries in the population.
- The statistic is proportion of driver dummies (if they had been real people) who would have suffered head injuries in the sample.
- The variable \(X\) = the number of driver dummies (if they had been real people) who would have suffered head injuries.
- The data are either: yes, had head injury, or no, did not.
Example \(\PageIndex{4}\)
Determine what the key terms refer to in the following study.
An insurance company would like to determine the proportion of all medical doctors who have been involved in one or more malpractice lawsuits. The company selects 500 doctors at random from a professional directory and determines the number in the sample who have been involved in a malpractice lawsuit.
Answer
- The population is all medical doctors listed in the professional directory.
- The parameter is the proportion of medical doctors who have been involved in one or more malpractice suits in the population.
- The sample is the 500 doctors selected at random from the professional directory.
- The statistic is the proportion of medical doctors who have been involved in one or more malpractice suits in the sample.
- The variable \(X\) = the number of medical doctors who have been involved in one or more malpractice suits.
- The data are either: yes, was involved in one or more malpractice lawsuits, or no, was not.
Collaborative Exercise
Do the following exercise collaboratively with up to four people per group. Find a population, a sample, the parameter, the statistic, a variable, and data for the following study: You want to determine the average (mean) number of glasses of milk college students drink per day. Suppose yesterday, in your English class, you asked five students how many glasses of milk they drank the day before. The answers were 1, 0, 1, 3, and 4 glasses of milk.
Practice
Use the following information to answer the next five exercises. Studies are often done by pharmaceutical companies to determine the effectiveness of a treatment program. Suppose that a new AIDS antibody drug is currently under study. It is given to patients once the AIDS symptoms have revealed themselves. Of interest is the average (mean) length of time in months patients live once they start the treatment. Two researchers each follow a different set of 40 patients with AIDS from the start of treatment until their deaths. The following data (in months) are collected.
Researcher A:
3; 4; 11; 15; 16; 17; 22; 44; 37; 16; 14; 24; 25; 15; 26; 27; 33; 29; 35; 44; 13; 21; 22; 10; 12; 8; 40; 32; 26; 27; 31; 34; 29; 17; 8; 24; 18; 47; 33; 34
Researcher B:
3; 14; 11; 5; 16; 17; 28; 41; 31; 18; 14; 14; 26; 25; 21; 22; 31; 2; 35; 44; 23; 21; 21; 16; 12; 18; 41; 22; 16; 25; 33; 34; 29; 13; 18; 24; 23; 42; 33; 29
Determine what the key terms refer to in the example for Researcher A.
Exercise \(\PageIndex{2}\)
population
Answer
AIDS patients.
Exercise \(\PageIndex{3}\)
sample
Exercise \(\PageIndex{4}\)
parameter
Answer
The average length of time (in months) AIDS patients live after treatment.
Exercise \(\PageIndex{5}\)
statistic
Exercise \(\PageIndex{6}\)
variable
Answer
\(X =\) the length of time (in months) AIDS patients live after treatment
Glossary
The mathematical theory of statistics is easier to learn when you know the language. This module presents important terms that will be used throughout the text.
- Average
- also called mean; a number that describes the central tendency of the data
- Categorical Variable
- variables that take on values that are names or labels
- Data
- a set of observations (a set of possible outcomes); most data can be put into two groups: qualitative(an attribute whose value is indicated by a label) or quantitative (an attribute whose value is indicated by a number). Quantitative data can be separated into two subgroups: discrete and continuous. Data is discrete if it is the result of counting (such as the number of students of a given ethnic group in a class or the number of books on a shelf). Data is continuous if it is the result of measuring (such as distance traveled or weight of luggage)
- Numerical Variable
- variables that take on values that are indicated by numbers
- Parameter
- a number that is used to represent a population characteristic and that generally cannot be determined easily
- Population
- all individuals, objects, or measurements whose properties are being studied
- Probability
- a number between zero and one, inclusive, that gives the likelihood that a specific event will occur
- Proportion
- the number of successes divided by the total number in the sample
- Representative Sample
- a subset of the population that has the same characteristics as the population
- Sample
- a subset of the population studied
- Statistic
- a numerical characteristic of the sample; a statistic estimates the corresponding population parameter.
- Variable
- a characteristic of interest for each person or object in a population
Contributors and Attributions
Barbara Illowsky and Susan Dean (De Anza College) with many other contributing authors. Content produced by OpenStax College is licensed under a Creative Commons Attribution License 4.0 license. Download for free at http://cnx.org/contents/30189442-699...b91b9de@18.114.
- Back to top
- There are no recommended articles.
- Article type
- Section or Page
- Author
- OpenStax
- License
- CC BY
- Show TOC
- no
- Tags
- parameter
- population
- probability
- statistic
- variable
What’s New in the Poker Analyzer 1.2 serial key or number?
Screen Shot
System Requirements for Poker Analyzer 1.2 serial key or number
- First, download the Poker Analyzer 1.2 serial key or number
-
You can download its setup from given links:

Poker Analyzer 1.2 serial key or number & Key Download

Poker Analyzer 1.2 serial key or number& Kali Software Crack
