
Mobile Net Switch v3.1 serial key or number

Mobile Net Switch v3.1 serial key or number
Product overview
Cisco® Catalyst® 1000 Series Switches are fixed managed Gigabit Ethernet enterprise-class Layer 2 switches designed for small businesses and branch offices. These are simple, flexible and secure switches ideal for out-of-the-wiring-closet and critical Internet of Things (IoT) deployments. Cisco® Catalyst® 1000 operate on Cisco IOS® Software and support simple device management and network management via a Command-Line Interface (CLI) as well as an on-box web UI. These switches deliver enhanced network security, network reliability, and operational efficiency for small organizations.
Product highlights
Cisco Catalyst 1000 Series Switches feature:
● 8, 16, 24, or 48 Gigabit Ethernet data or PoE+ ports with line-rate forwarding
● 2 or 4 fixed 1 Gigabit Ethernet Small Form-Factor Pluggable (SFP)/RJ 45 Combo uplinks or 4 fixed 0 Gigabit Ethernet Enhanced SFP (SFP+) uplinks
● Perpetual PoE+ support with a power budget of up to 740W
● CLI and/or intuitive web UI manageability options
● Network monitoring through sampled flow (sFlow)
● Security with 802.1X support for connected devices, Switched Port Analyzer (SPAN), and Bridge Protocol Data Unit (BPDU) Guard
● Compact fanless models available with a depth of less than 13 inches (33 cm)
● Device management support with over-the-air access via Bluetooth, Simple Network Management Protocol (SNMP), RJ-45, or USB console acces
● Reliability with a higher Mean Time Between Failures (MTBF) and an enhanced limited lifetime warranty support(E-LLW)
Switch models and configurations
Cisco Catalyst 1000 Series Switches include a single fixed power supply. Table 1 shows configuration information.
Table 1. Switch configurations
Product ID* | Gigabit Ethernet ports | Uplink interfaces | PoE+power budget | Fanless | Dimensions (WxDxH in inches) | Weight (kg) |
C1000-8T-2G-L | 8 | 2 SFP/ RJ-45 combo | – | Y | 10.56 x 7.28 x 1.73 | 1.80 |
C1000-8T-E-2G-L | 8 | 2 SFP/ RJ-45 combo | – | Y | 10.56 x 7.28 x 1.73 | 1.55 |
C1000-8P-2G-L | 8 | 2 SFP/ RJ-45 combo | 67W | Y | 10.56 x 12.73 x 1.73 | 1.55 |
C1000-8P-E-2G-L | 8 | 2 SFP/ RJ-45 combo | 67W | Y | 10.56 x 7.28 x 1.73 | 1.55 |
C1000-8FP-2G-L | 8 | 2 SFP/ RJ-45 combo | 120W | Y | 10.56 x 12.73 x 1.73 | 2.70 |
C1000-8FP-E-2G-L | 8 | 2 SFP/ RJ-45 combo | 120W | Y | 10.56 x 7.28 x 1.73 | 2.70 |
C1000-16T-2G-L | 16 | 2 SFP | – | Y | 10.56 x 10.69 x 1.73 | 1.78 |
C1000-16T-E-2G-L | 16 | 2 SFP | - | Y | 10.56 x 8.26 x 1.73 | 1.42 |
C1000-16P-2G-L | 16 | 2 SFP | 120W | Y | 10.56 x 11.69 x 1.73 | 2.38 |
C1000-16P-E-2G-L | 16 | 2 SFP | 120W | Y | 10.56 x 8.26x 1.73 | 1.42 |
C1000-16FP-2G-L | 16 | 2 SFP | 240W | Y | 10.56 x 12.14 x 1.73 | 2.49 |
C1000-24T-4G-L | 24 | 4 SFP | - | Y | 17.5 x 9.45 x 1.73 | 2.63 |
C1000-24P-4G-L | 24 | 4 SFP | 195W | Y | 17.5 x 11.76 x 1.73 | 3.53 |
C1000-24FP-4G-L | 24 | 4 SFP | 370W | N | 17.5 x 13.59 x 1.73 | 4.6 |
C1000-48T-4G-L | 48 | 4 SFP | - | N | 17.5 x 10.73 x 1.73 | 3.95 |
C1000-48P-4G-L | 48 | 4 SFP | 370W | N | 17.5 x 13.78 x 1.73 | 5.43 |
C1000-48FP-4G-L | 48 | 4 SFP | 740W | N | 17.5 x 13.78 x 1.73 | 5.82 |
C1000-24T-4X-L | 24 | 4 SFP+ | - | Y | 17.5 x 9.45 x 1.73 | 2.78 |
C1000-24P-4X-L | 24 | 4 SFP+ | 195W | Y | 17.5 x 11.76 x 1.73 | 3.68 |
C1000-24FP-4X-L | 24 | 4 SFP+ | 370W | N | 17.5 x 13.59 x 1.73 | 4.6 |
C1000-48T-4X-L | 48 | 4 SFP+ | - | N | 17.5 x 10.73 x 1.73 | 3.95 |
C1000-48P-4X-L | 48 | 4 SFP+ | 370W | N | 17.5 x 13.78 x 1.73 | 5.43 |
C1000-48FP-4X-L | 48 | 4 SFP+ | 740W | N | 17.5 x 13.78 x 1.73 | 5.82 |
Software
The software features supported on the Cisco Catalyst 1000 Series can be found on Cisco Feature Navigator: https://cfn.cloudapps.cisco.com/ITDIT/CFN/jsp/by-feature-technology.jsp
Switch management
Cisco Catalyst 1000 Series Switches support the following on-device management features:
● Web UI via Cisco Configuration Professional. Cisco Configuration Professional provides a user interface for day-zero provisioning, which enables easy onboarding of the switch. It also has an intuitive dashboard for configuring, monitoring, and troubleshooting the switch (Figure 1). For more information, about Cisco Configuration Professional, refer to https://www.cisco.com/c/en/us/products/cloud-systems-management/configuration-professional-catalyst/index.html.
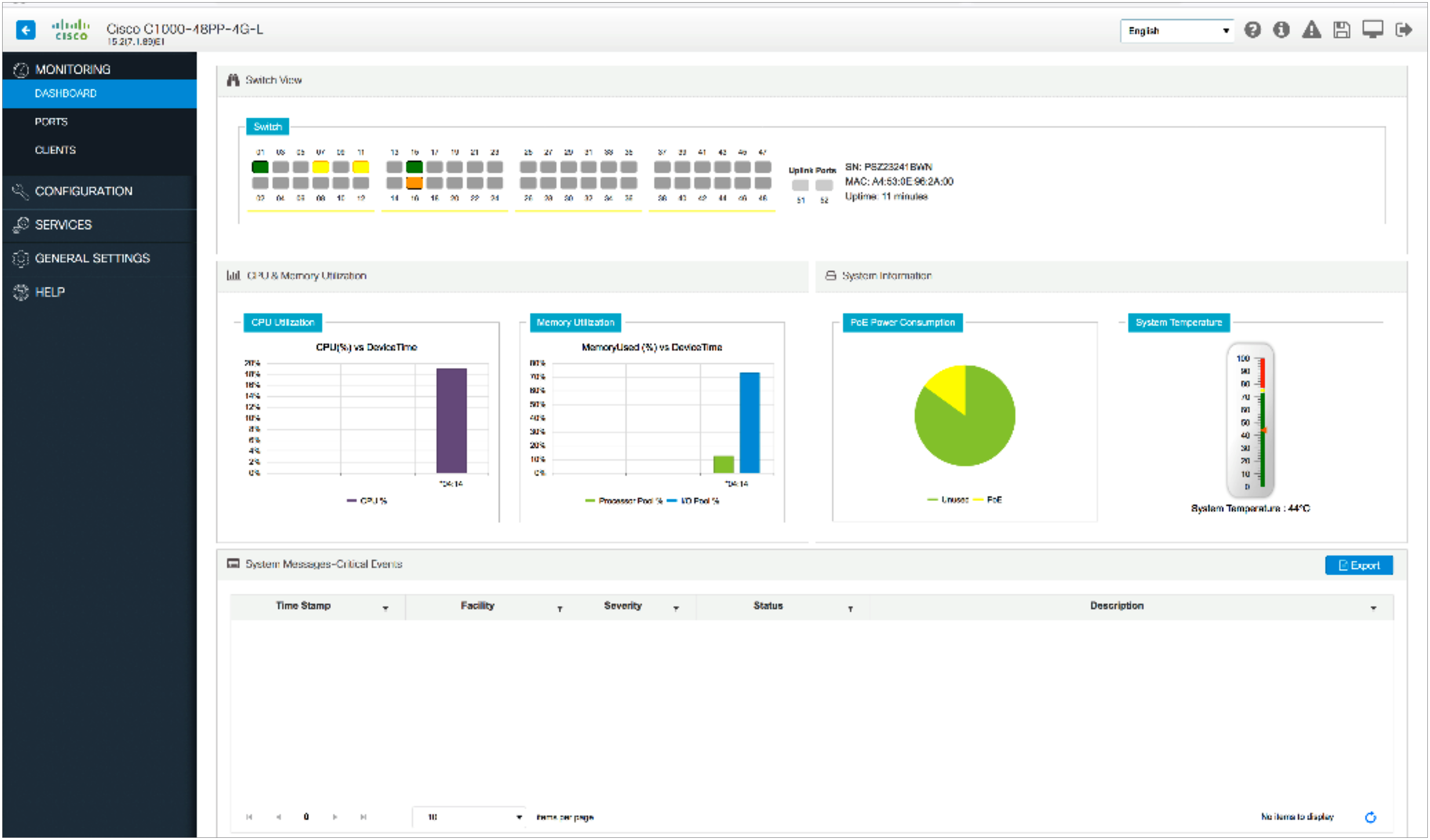
Cisco Configuration Professional
● Bluetooth for over-the-air access. The switches support an external Bluetooth dongle that plugs into the USB port on the switch and allows a Bluetooth-based RF connection with external laptops and tablets (Figure 2). Laptops and tablets can access the switch CLI using a Telnet or Secure Shell (SSH) client over Bluetooth. The GUI can be accessed over Bluetooth with a browser.

Over-the-air switch access using Bluetooth
● Single IP Management is available on the Cisco Catalyst 1000 Series switches. The uplink ports can be used to connect up to eight switches and manage them via a single IP address.
Network management
The Cisco Catalyst 1000 Series Switches offer a superior CLI for detailed configuration and administration.
Intelligent PoE+
Cisco Catalyst 1000 Series Switches support both IEEE 802.3af PoE and IEEE 802.3at PoE+ (up to 30W per port) to deliver a lower total cost of ownership for deployments that incorporate Cisco IP phones, Cisco Aironet® and Catalyst wireless access points, or other standards-compliant PoE and PoE+ end devices. PoE removes the need to supply wall power to PoE-enabled devices and eliminates the cost of adding electrical cabling and circuits that would otherwise be necessary in IP phone and WLAN deployments.
The PoE power allocation in the Cisco Catalyst 1000 Series Switches is dynamic, and power mapping scales up to a maximum of 740W of PoE+ power. Intelligent power management allows flexible power allocation across all ports. With Perpetual PoE, the PoE+ power is maintained during a switch reload. This is important for critical endpoints such as medical devices and for IoT endpoints such as PoE-powered lights, so that there is no disruption during a switch reboot.
Network security
Cisco Catalyst 1000 Series Switches provide a range of security features to limit access to the network and mitigate threats, including:
● Comprehensive 802.1X features to control access to the network, including flexible authentication, 802.1X monitor mode, and RADIUS change of authorization.
● 802.1X support with Network Edge Access Topology (NEAT), which extends identity authentication to areas outside the wiring closet (such as conference rooms).
● IEEE 802.1X user distribution, which enables you to load-balance users with the same group name across multiple different VLANs.
● Ability to disable per-VLAN MAC learning to allow you to manage the available MAC address table space by controlling which interface or VLANs learn MAC addresses.
● Multidomain authentication to allow an IP phone and a PC to authenticate on the same switch port while being placed on the appropriate voice and data VLANs.
● Authentication, Authorization, and Accounting (AAA) command authorization in PnP to enable seamless PnP provisioning.
● Access Control Lists (ACLS) for IPv6 and IPv4 security and Quality-of-Service (QoS) ACL elements (ACEs).
● Port-based ACLs for Layer 2 interfaces to allow security policies to be applied on individual switch ports.
● SSH, Kerberos, and SNMP v3 to provide network security by encrypting administrator traffic during Telnet and SNMP sessions. SSH, Kerberos, and the cryptographic version of SNMP v3 require a special cryptographic software image because of U.S. export restrictions.
● SPAN, with bidirectional data support, to allow the Cisco Intrusion Detection System (IDS) to take action when an intruder is detected.
● TACACS+ and RADIUS authentication to facilitate centralized control of the switch and restrict unauthorized users from altering the configuration.
● MAC address notification to notify administrators about users added to or removed from the network.
● MAC Authentication Bypass (MAB) and WebAuth with downloadable ACLs to allow per-user ACLs to be downloaded from the Cisco Identity Services Engine (ISE) as policy enforcement after authentication using MAB or web authentication in addition to IEEE 802.1X.
● Web authentication redirection to enable networks to redirect guest users to the URL they had originally requested.
● Multilevel security on console access to prevent unauthorized users from altering the switch configuration.
● BPDU Guard to shut down Spanning Tree PortFast-enabled interfaces when BPDUs are received, to avoid accidental topology loops.
● IP Source Guard to restrict IP traffic on nonrouted Layer 2 interfaces by filtering traffic based on the Dynamic Host Configuration Protocol (DHCP) snooping binding database or by manually configuring IP source bindings.
● SSH v2 to allow use of digital certificates for authentication between user and server.
● Spanning Tree Root Guard (STRG) to prevent edge devices that are not in the network administrator’s control from becoming Spanning Tree Protocol (STP) root nodes.
● Internet Group Management Protocol (IGMP) filtering to provide multicast authentication by filtering out nonsubscribers and to limit the number of concurrent multicast streams available per port.
● Dynamic VLAN assignment through implementation of VLAN Membership Policy Server client capability to provide flexibility in assigning ports to VLANs. Dynamic VLAN facilitates the fast assignment of IP addresses.
Redundancy and resiliency
Cisco Catalyst 1000 Series Switches offer a number of redundancy and resiliency features to prevent outages and help ensure that the network remains available:
● IEEE 802.1s/w Rapid Spanning Tree Protocol (RSTP) and Multiple Spanning Tree Protocol (MSTP) provide rapid spanning-tree convergence independent of spanning-tree timers and also offer the benefits of Layer 2 load balancing and distributed processing.
● Per-VLAN Rapid Spanning Tree (PVRST+) allows rapid spanning-tree reconvergence on a per-VLAN spanning-tree basis, without requiring the implementation of spanning-tree instances.
● Switch-port auto-recovery (error disable) automatically attempts to reactivate a link that is disabled because of a network error.
● Link state tracking binds the link state of multiple interfaces. The server Network Interface Cards (NICs) form a group to provide redundancy in the network. When the link is lost on the primary interface, network connectivity is transparently changed to the secondary interface.
Enhanced QoS
Cisco Catalyst 1000 Series Switches offer intelligent traffic management that keeps everything flowing smoothly. Flexible mechanisms for marking, classifying, and scheduling deliver superior performance for data, voice, and video traffic, all at wire speed. Primary QoS features include:
● Up to eight egress queues and two thresholds per port, supporting egress bandwidth control, shaping, and priority queuing so that high-priority packets are serviced ahead of other traffic.
● Ingress policing to allow the analysis of IP service levels for IP applications and services using active traffic monitoring — generating traffic in a continuous, reliable, and predictable manner — for measuring network performance. The number of ingress policers available per port is 64.
● QoS through Differentiated Services Code Point (DSCP) mapping and filtering.
● QoS through traffic classification.
● Trust boundary to configure device-based trust.
● AutoQoS to simplify the deployment of QoS features.
● Shaped Round Robin (SRR) scheduling and Weighted Tail Drop (WTD) congestion avoidance.
● 802.1p Class of Service (CoS) classification, with marking and reclassification.
Energy management
Cisco Catalyst 1000 Series Switches offer a range of industry-leading features for energy efficiency and management:
● IEEE 802.3az Energy Efficient Ethernet (EEE) enables ports to dynamically sense idle periods between traffic bursts and quickly switch the interfaces into a low-power idle mode, reducing power consumption.
● Loop detection is a new method to detect network loops in the absence of STP.
● Cisco AutoConfig determines the level of network access provided to an endpoint based on the type of device. This feature also permits hard binding between the end device and the interface.
● Cisco Auto SmartPorts enables automatic configuration of switch ports as devices connect to the switch with settings optimized for the device type, resulting in zero-touch port-policy provisioning.
● Cisco Smart Troubleshooting is an extensive array of diagnostic commands and system health checks in the switch, including Smart Call Home. The Cisco Generic Online Diagnostics (GOLD) and online diagnostics on switches in live networks help predict and detect failures more quickly.
For more information about Cisco Catalyst SmartOperations, visit cisco.com/go/SmartOperations.
Operational simplicity
● Cisco AutoSecure provides a single-line CLI to enable baseline security features (port security, DHCP snooping, Dynamic Address Resolution Protocol [ARP] Inspection). This feature simplifies security configurations with a single touch.
● DHCP auto configuration of multiple switches through a boot server eases switch deployment.
● Auto negotiation on all ports automatically selects half- or full-duplex transmission mode to optimize bandwidth.
● Dynamic Trunking Protocol (DTP) facilitates dynamic trunk configuration across all switch ports.
● Port Aggregation Protocol (PAgP) automates the creation of Cisco Fast EtherChannel groups or Gigabit EtherChannel groups to link to another switch, router, or server.
● Link Aggregation Control Protocol (LACP) allows the creation of Ethernet channeling with devices that conform to IEEE 802.3ad. This feature is similar to Cisco EtherChannel technology and PAgP.
● Automatic Media-Dependent Interface Crossover (MDIX) automatically adjusts transmit and receive pairs if an incorrect cable type (crossover or straight-through) is installed.
● Unidirectional Link Detection Protocol (UDLD) and Aggressive UDLD allow unidirectional links caused by incorrect fiber-optic wiring or port faults to be detected and disabled on fiber-optic interfaces.
● Local Proxy ARP works in conjunction with Private VLAN Edge to minimize broadcasts and maximize available bandwidth.
● VLAN1 minimization allows VLAN1 to be disabled on any individual VLAN trunk.
● IGMP snooping for IPv4 and IPv6 and Multicast Listener Discovery (MLD) v1 and v2 snooping provide fast client joins and leaves of multicast streams and limit bandwidth-intensive video traffic to only the requesters.
● Per-port broadcast, multicast, and unicast storm control prevents faulty end stations from degrading overall system performance.
● Voice VLAN simplifies telephony installations by keeping voice traffic on a separate VLAN for easier administration and troubleshooting.
● Cisco VLAN Trunking Protocol (VTP) supports dynamic VLANs and dynamic trunk configuration across all switches.
● Layer 2 trace route eases troubleshooting by identifying the physical path that a packet takes from source to destination.
● Trivial File Transfer Protocol (TFTP) reduces the cost of administering software upgrades by downloading from a centralized location.
● Network Time Protocol (NTP) provides an accurate and consistent timestamp to all intranet switches.
Specifications
Product specifications (Table 2) apply to both PoE and non-PoE models.
Table 2. Specifications
| 8-port models | 16-port models | 24-port models (1/10G uplinks) | 48-port models (1/10G uplinks) | ||||
Console ports | ||||||||
RJ-45 Ethernet | 1 | 1 | 1 | 1 | ||||
USB mini-B | 1 | 1 | 1 | 1 | ||||
USB-A port for storage and Bluetooth console | 1 | 1 | 1 | 1 | ||||
Memory and processor | ||||||||
CPU | ARM v7 800 MHz | ARM v7 800 MHz | ARM v7 800 MHz | ARM v7 800 MHz | ||||
DRAM | 512 MB | 512 MB | 512 MB | 512 MB | ||||
Flash memory | 256 MB | 256 MB | 256 MB | |||||
Software cracking
Software cracking (known as "breaking" in the 1980s[1]) is the modification of software to remove or disable features which are considered undesirable by the person cracking the software, especially copy protection features (including protection against the manipulation of software, serial number, hardware key, date checks and disc check) or software annoyances like nag screens and adware.
A crack refers to the means of achieving, for example a stolen serial number or a tool that performs that act of cracking.[2] Some of these tools are called keygen, patch, or loader. A keygen is a handmade product serial number generator that often offers the ability to generate working serial numbers in your own name. A patch is a small computer program that modifies the machine code of another program. This has the advantage for a cracker to not include a large executable in a release when only a few bytes are changed.[3] A loader modifies the startup flow of a program and does not remove the protection but circumvents it.[4][5] A well-known example of a loader is a trainer used to cheat in games.[6]Fairlight pointed out in one of their .nfo files that these type of cracks are not allowed for warez scene game releases.[7][4][8] A nukewar has shown that the protection may not kick in at any point for it to be a valid crack.[9]
The distribution of cracked copies is illegal in most countries. There have been lawsuits over cracking software.[10] It might be legal to use cracked software in certain circumstances.[11] Educational resources for reverse engineering and software cracking are, however, legal and available in the form of Crackme programs.
History[edit]
The first software copy protection was applied to software for the Apple II,[12]Atari 800, and Commodore 64 computers.[citation needed]. Software publishers have implemented increasingly complex methods in an effort to stop unauthorized copying of software.
On the Apple II, unlike modern computers that use standardized device drivers to manage device communications, the operating system directly controlled the step motor that moves the floppy drive head, and also directly interpreted the raw data, called nibbles, read from each track to identify the data sectors. This allowed complex disk-based software copy protection, by storing data on half tracks (0, 1, 2.5, 3.5, 5, 6...), quarter tracks (0, 1, 2.25, 3.75, 5, 6...), and any combination thereof. In addition, tracks did not need to be perfect rings, but could be sectioned so that sectors could be staggered across overlapping offset tracks, the most extreme version being known as spiral tracking. It was also discovered that many floppy drives did not have a fixed upper limit to head movement, and it was sometimes possible to write an additional 36th track above the normal 35 tracks. The standard Apple II copy programs could not read such protected floppy disks, since the standard DOS assumed that all disks had a uniform 35-track, 13- or 16-sector layout. Special nibble-copy programs such as Locksmith and Copy II Plus could sometimes duplicate these disks by using a reference library of known protection methods; when protected programs were cracked they would be completely stripped of the copy protection system, and transferred onto a standard format disk that any normal Apple II copy program could read.
One of the primary routes to hacking these early copy protections was to run a program that simulates the normal CPU operation. The CPU simulator provides a number of extra features to the hacker, such as the ability to single-step through each processor instruction and to examine the CPU registers and modified memory spaces as the simulation runs (any modern disassembler/debugger can do this). The Apple II provided a built-in opcode disassembler, allowing raw memory to be decoded into CPU opcodes, and this would be utilized to examine what the copy-protection was about to do next. Generally there was little to no defense available to the copy protection system, since all its secrets are made visible through the simulation. However, because the simulation itself must run on the original CPU, in addition to the software being hacked, the simulation would often run extremely slowly even at maximum speed.
On Atari 8-bit computers, the most common protection method was via "bad sectors". These were sectors on the disk that were intentionally unreadable by the disk drive. The software would look for these sectors when the program was loading and would stop loading if an error code was not returned when accessing these sectors. Special copy programs were available that would copy the disk and remember any bad sectors. The user could then use an application to spin the drive by constantly reading a single sector and display the drive RPM. With the disk drive top removed a small screwdriver could be used to slow the drive RPM below a certain point. Once the drive was slowed down the application could then go and write "bad sectors" where needed. When done the drive RPM was sped up back to normal and an uncracked copy was made. Of course cracking the software to expect good sectors made for readily copied disks without the need to meddle with the disk drive. As time went on more sophisticated methods were developed, but almost all involved some form of malformed disk data, such as a sector that might return different data on separate accesses due to bad data alignment. Products became available (from companies such as Happy Computers) which replaced the controller BIOS in Atari's "smart" drives. These upgraded drives allowed the user to make exact copies of the original program with copy protections in place on the new disk.
On the Commodore 64, several methods were used to protect software. For software distributed on ROM cartridges, subroutines were included which attempted to write over the program code. If the software was on ROM, nothing would happen, but if the software had been moved to RAM, the software would be disabled. Because of the operation of Commodore floppy drives, one write protection scheme would cause the floppy drive head to bang against the end of its rail, which could cause the drive head to become misaligned. In some cases, cracked versions of software were desirable to avoid this result. A misaligned drive head was rare usually fixing itself by smashing against the rail stops. Another brutal protection scheme was grinding from track 1 to 40 and back a few times.
Most of the early software crackers were computer hobbyists who often formed groups that competed against each other in the cracking and spreading of software. Breaking a new copy protection scheme as quickly as possible was often regarded as an opportunity to demonstrate one's technical superiority rather than a possibility of money-making. Some low skilled hobbyists would take already cracked software and edit various unencrypted strings of text in it to change messages a game would tell a game player, often something considered vulgar. Uploading the altered copies on file sharing networks provided a source of laughs for adult users. The cracker groups of the 1980s started to advertise themselves and their skills by attaching animated screens known as crack intros in the software programs they cracked and released. Once the technical competition had expanded from the challenges of cracking to the challenges of creating visually stunning intros, the foundations for a new subculture known as demoscene were established. Demoscene started to separate itself from the illegal "warez scene" during the 1990s and is now regarded as a completely different subculture. Many software crackers have later grown into extremely capable software reverse engineers; the deep knowledge of assembly required in order to crack protections enables them to reverse engineerdrivers in order to port them from binary-only drivers for Windows to drivers with source code for Linux and other free operating systems. Also because music and game intro was such an integral part of gaming the music format and graphics became very popular when hardware became affordable for the home user.
With the rise of the Internet, software crackers developed secretive online organizations. In the latter half of the nineties, one of the most respected sources of information about "software protection reversing" was Fravia's website.
Most of the well-known or "elite" cracking groups make software cracks entirely for respect in the "Scene", not profit. From there, the cracks are eventually leaked onto public Internet sites by people/crackers who use well-protected/secure FTP release archives, which are made into full copies and sometimes sold illegally by other parties.
The Scene today is formed of small groups of skilled people, who informally compete to have the best crackers, methods of cracking, and reverse engineering.
+HCU[edit]
The High Cracking University (+HCU), was founded by Old Red Cracker (+ORC), considered a genius of reverse engineering and a legendary figure in RCE, to advance research into Reverse Code Engineering (RCE). He had also taught and authored many papers on the subject, and his texts are considered classics in the field and are mandatory reading for students of RCE.[13]
The addition of the "+" sign in front of the nickname of a reverser signified membership in the +HCU. Amongst the students of +HCU were the top of the elite Windows reversers worldwide.[13] +HCU published a new reverse engineering problem annually and a small number of respondents with the best replies qualified for an undergraduate position at the university.[13]
+Fravia was a professor at +HCU. Fravia's website was known as "+Fravia's Pages of Reverse Engineering" and he used it to challenge programmers as well as the wider society to "reverse engineer" the "brainwashing of a corrupt and rampant materialism". In its heyday, his website received millions of visitors per year and its influence was "widespread".[13]
Nowadays most of the graduates of +HCU have migrated to Linux and few have remained as Windows reversers. The information at the university has been rediscovered by a new generation of researchers and practitioners of RCE who have started new research projects in the field.[13]
Methods[edit]
The most common software crack is the modification of an application's binary to cause or prevent a specific key branch in the program's execution. This is accomplished by reverse engineering the compiled program code using a debugger such as SoftICE,[14]x64dbg, OllyDbg,[15]GDB, or MacsBug until the software cracker reaches the subroutine that contains the primary method of protecting the software (or by disassembling an executable file with a program such as IDA). The binary is then modified using the debugger or a hex editor or monitor in a manner that replaces a prior branching opcode with its complement or a NOPopcode so the key branch will either always execute a specific subroutine or skip over it. Almost all common software cracks are a variation of this type. Proprietary software developers are constantly developing techniques such as code obfuscation, encryption, and self-modifying code to make this modification increasingly difficult. Even with these measures being taken, developers struggle to combat software cracking. This is because it is very common for a professional to publicly release a simple cracked EXE or Retrium Installer for public download, eliminating the need for inexperienced users to crack the software themselves.
A specific example of this technique is a crack that removes the expiration period from a time-limited trial of an application. These cracks are usually programs that alter the program executable and sometimes the .dll or .so linked to the application. Similar cracks are available for software that requires a hardware dongle. A company can also break the copy protection of programs that they have legally purchased but that are licensed to particular hardware, so that there is no risk of downtime due to hardware failure (and, of course, no need to restrict oneself to running the software on bought hardware only).
Another method is the use of special software such as CloneCD to scan for the use of a commercial copy protection application. After discovering the software used to protect the application, another tool may be used to remove the copy protection from the software on the CD or DVD. This may enable another program such as Alcohol 120%, CloneDVD, Game Jackal, or Daemon Tools to copy the protected software to a user's hard disk. Popular commercial copy protection applications which may be scanned for include SafeDisc and StarForce.[16]
In other cases, it might be possible to decompile a program in order to get access to the original source code or code on a level higher than machine code. This is often possible with scripting languages and languages utilizing JIT compilation. An example is cracking (or debugging) on the .NET platform where one might consider manipulating CIL to achieve one's needs. Java'sbytecode also works in a similar fashion in which there is an intermediate language before the program is compiled to run on the platform dependent machine code.
Advanced reverse engineering for protections such as SecuROM, SafeDisc, StarForce, or Denuvo requires a cracker, or many crackers to spend much time studying the protection, eventually finding every flaw within the protection code, and then coding their own tools to "unwrap" the protection automatically from executable (.EXE) and library (.DLL) files.
There are a number of sites on the Internet that let users download cracks produced by warez groups for popular games and applications (although at the danger of acquiring malicious software that is sometimes distributed via such sites).[17] Although these cracks are used by legal buyers of software, they can also be used by people who have downloaded or otherwise obtained unauthorized copies (often through P2P networks).
Trial reset[edit]
Many commercial programs that can be downloaded from the Internet have a trial period (often 30 days) and must be registered (i.e. be bought) after its expiration if the user wants to continue to use them. To reset the trial period, registry entries and/or hidden files that contain information about the trial period are modified and/or deleted. For this purpose, crackers develop "trial resetters" for a particular program or sometimes also for a group of programs by the same manufacturer.
A method to make trial resets less attractive is the limitation of the software during the trial period (e.g., some features are only available in the registered version; pictures/videos/hardcopies created with the program get a watermark; the program runs for only 10–20 minutes and then closes automatically). Some programs have an unlimited trial period, but are limited until their registration.
See also[edit]
References[edit]
- ^Kevelson, Morton (October 1985). "Isepic". Ahoy!. pp. 71–73. Retrieved June 27, 2014.
- ^Tulloch, Mitch (2003). Microsoft Encyclopedia of Security(PDF). Redmond, Washington: Microsoft Press. p. 68. ISBN .
- ^Craig, Paul; Ron, Mark (April 2005). "Chapter 4: Crackers". In Burnett, Mark (ed.). Software Piracy Exposed - Secrets from the Dark Side Revealed. Publisher: Andrew Williams, Page Layout and Art: Patricia Lupien, Acquisitions Editor: Jaime Quigley, Copy Editor: Judy Eby, Technical Editor: Mark Burnett, Indexer: Nara Wood, Cover Designer: Michael Kavish. United States of America: Syngress Publishing. pp. 75–76. doi:10.1016/B978-193226698-6/50029-5. ISBN .
- ^ abFLT (January 22, 2013). "The_Sims_3_70s_80s_and_90s_Stuff-FLT".
- ^Shub-Nigurrath [ARTeam]; ThunderPwr [ARTeam] (January 2006). "Cracking with Loaders: Theory, General Approach, and a Framework". CodeBreakers Magazine. Universitas-Virtualis Research Project. 1 (1).
- ^Nigurrath, Shub (May 2006). "Guide on how to play with processes memory, writing loaders, and Oraculumns". CodeBreakers Magazine. Universitas-Virtualis Research Project. 1 (2).
- ^FLT (September 29, 2013). "Test_Drive_Ferrari_Legends_PROPER-FLT".
- ^SKIDROW (January 21, 2013). "Test.Drive.Ferrari.Racing.Legends.Read.Nfo-SKIDROW".
- ^"Batman.Arkham.City-FiGHTCLUB nukewar". December 2, 2011. Archived from the original on September 13, 2014.
- ^Cheng, Jacqui (September 27, 2006). "Microsoft files lawsuit over DRM crack". Ars Technica.
- ^Fravia (November 1998). "Is reverse engineering legal?".
- ^Pearson, Jordan (July 24, 2017). "Programmers Are Racing to Save Apple II Software Before It Goes Extinct". Motherboard. Archived from the original on September 27, 2017. Retrieved January 27, 2018.
- ^ abcdeCyrus Peikari; Anton Chuvakin (January 12, 2004). Security Warrior. "O'Reilly Media, Inc.". p. 31. ISBN .
- ^Ankit, Jain; Jason, Kuo; Jordan, Soet; Brian, Tse (April 2007). "Software Cracking (April 2007)"(PDF). The University of British Columbia - Electrical and Computer Engineering. Retrieved January 27, 2018.Cite journal requires (help)
- ^Wójcik, Bartosz. "Reverse engineering tools review". pelock.com. PELock. Archived from the original on September 13, 2017. Retrieved February 16, 2018.
- ^Gamecopyworld Howto
- ^McCandless, David (April 1, 1997). "Warez Wars". Wired. ISSN 1059-1028. Retrieved February 4, 2020.
Announcing .NET Core 3.0

Richard
September 23rd, 2019
We’re excited to announce the release of .NET Core 3.0. It includes many improvements, including adding Windows Forms and WPF, adding new JSON APIs, support for ARM64 and improving performance across the board. C# 8 is also part of this release, which includes nullable, async streams, and more patterns. F# 4.7 is included, and focused on relaxing syntax and targeting .NET Standard 2.0. You can start updating existing projects to target .NET Core 3.0 today. The release is compatible with previous versions, making updating easy.
Watch the team and the community talk about .NET at .NET Conf, live NOW!
You can download .NET Core 3.0, for Windows, macOS, and Linux:
ASP.NET Core 3.0 and EF Core 3.0 are also releasing today.
Visual Studio 2019 16.3 and Visual Studio for Mac 8.3 were also released today and are required update to use .NET Core 3.0 with Visual Studio. .NET Core 3.0 is part of Visual Studio 2019 16.3. You can just get .NET Core by simply upgrading Visual Studio 2019 16.3.
Thank you to everyone that contributed to .NET Core 3.0! Hundreds of people were involved in making this release happen, including major contributions from the community.
Release notes:
Note: There are some contributors missing from the contributor list. We’re working on fixing that. Send mail to dotnet@microsoft.com if you are missing.
What you should know about 3.0
There are some key improvements and guidance that are important to draw attention to before we go into a deep dive on all the new features in .NET Core 3.0. Here’s the quick punch list.
- .NET Core 3.0 is already battle-tested by being hosted for months at dot.net and on Bing.com. Many other Microsoft teams will soon be deploying large workloads on .NET Core 3.0 in production.
- Performance is greatly improved across many components and is described in detail at Performance Improvements in .NET Core 3.0.
- C# 8 add async streams, range/index, more patterns, and nullable reference types. Nullable enables you to directly target the flaws in code that lead to . The lowest layer of the framework libraries has been annotated, so that you know when to expect .
- F# 4.7 focuses on making some thing easier with implicit expressions and some syntax relaxations. It also includes support for , and ships with and opening of static classes in preview. The F# Core Library now also targets .NET Standard 2.0. You can read more at Announcing F# 4.7.
- .NET Standard 2.1 increases the set of types you can use in code that can be used with both .NET Core and Xamarin. .NET Standard 2.1 includes types since .NET Core 2.1.
- Windows Desktop apps are now supported with .NET Core, for both Windows Forms and WPF (and open source). The WPF designer is part of Visual Studio 2019 16.3. The Windows Forms designer is still in preview and available as a VSIX download.
- .NET Core apps now have executables by default. In past releases, apps needed to be launched via the command, like . Apps can now be launched with an app-specific executable, like or , depending on the operating system.
- High performance JSON APIs have been added, for reader/writer, object model and serialization scenarios. These APIs were built from scratch on top of and use UTF-8 under the covers instead of UTF-16 (like ). These APIs minimize allocations, resulting in faster performance, and much less work for the garbage collector. See The future of JSON in .NET Core 3.0.
- The garbage collector uses less memory by default, often a lot less. This improvement is very beneficial for scenarios where many applications are hosted on the same server. The garbage collector has also been updated to make better use of large numbers of cores, on machines with >64 cores.
- .NET Core has been hardened for Docker to enable .NET applications to work predictably and efficiently in containers. The garbage collector and thread pool have been updated to work much better when a container has been configured for limited memory or CPU. .NET Core docker images are smaller, particularly the SDK image.
- Raspberry Pi and ARM chips are now supported to enable IoT development, including with the remote Visual Studio debugger. You can deploy apps that listen to sensors, and print messages or images on a display, all using the new GPIO APIs. ASP.NET can be used to expose data as an API or as a site that enables configuring an IoT device.
- .NET Core 3.0 is a ‘current’ release and will be superseded by .NET Core 3.1, targeted for November 2019. .NET Core 3.1 will be a long-term supported (LTS) release (supported for at least 3 years). We recommend that you adopt .NET Core 3.0 and then adopt 3.1. It’ll be very easy to upgrade.
- .NET Core 2.2 will go EOL on 12/23 as it is now the previous ‘current’ release. See .NET Core support policy.
- .NET Core 3.0 will be available with RHEL 8 in the Red Hat Application Streams, after several years of collaboration with Red Hat.
- Visual Studio 2019 16.3 is a required update for Visual Studio users on Windows that want to use .NET Core 3.0.
- Visual Studio for Mac 8.3 is a required update for Visual Studio for Mac users that want to use .NET Core 3.0.
- Visual Studio Code users should just always use the latest version of the C# extension to ensure that the newest scenarios work, including targeting .NET Core 3.0.
- Azure App Service deployment of .NET Core 3.0 is currently ongoing. See our tracking site to track when .NET Core 3.0 is available in your region.
- Azure DevOps deployment of .NET Core 3.0 is coming soon. Will update when it is available.
Platform support
.NET Core 3.0 is supported on the following operating systems:
- Alpine: 3.9+
- Debian: 9+
- openSUSE: 42.3+
- Fedora: 26+
- Ubuntu: 16.04+
- RHEL: 6+
- SLES: 12+
- macOS: 10.13+
- Windows Client: 7, 8.1, 10 (1607+)
- Windows Server: 2012 R2 SP1+
Note: Windows Forms and WPF apps only work on Windows.
Chip support follows:
- x64 on Windows, macOS, and Linux
- x86 on Windows
- ARM32 on Windows and Linux
- ARM64 on Linux (kernel 4.14+)
Note: Please ensure that .NET Core 3.0 ARM64 deployments use Linux kernel 4.14 version or later. For example, Ubuntu 18.04 satisfies this requirement, but 16.04 does not.
WPF and Windows Forms
You can build WPF and Windows Forms apps with .NET Core 3, on Windows. We’ve had a strong compatibility goal from the start of the project, to make it easy to migrate desktop applications from .NET Framework to .NET Core. We’ve heard feedback from many developers that have already successfully ported their app to .NET Core 3.0 that the process is straightforward. To a large degree, we took WPF and Windows Forms as-is, and got them working on .NET Core. The engineering project was very different than that, but that’s a good way to think about the project.
The following image shows a .NET Core Windows Forms app:
Visual Studio 2019 16.3 has support for creating WPF apps that target .NET Core. This includes new templates and an updated XAML designer and XAML Hot Reload. The designer is similar to the existing XAML designer (that targets .NET Framework), however, you may notice some differences in experience. The big technical difference is that the designer for .NET Core uses a new surface process (wpfsurface.exe) to solely run the runtime code targeting the .NET Core version. Previously, the .NET Framework WPF designer process (xdesproc.exe) was a itself a WPF .NET Framework process hosting the designer, and due to runtime incompatibility we can’t have a WPF .NET Framework process (in this case, Visual Studio) loading two versions of .NET (.NET Framework and .NET Core) into the same process. This means that some aspects of the designer, like designer extensions, can’t work in the same way. If you are writing designer extensions, we recommend reading XAML designer extensibility migration.
The following image shows a WPF app being displayed in the new designer:
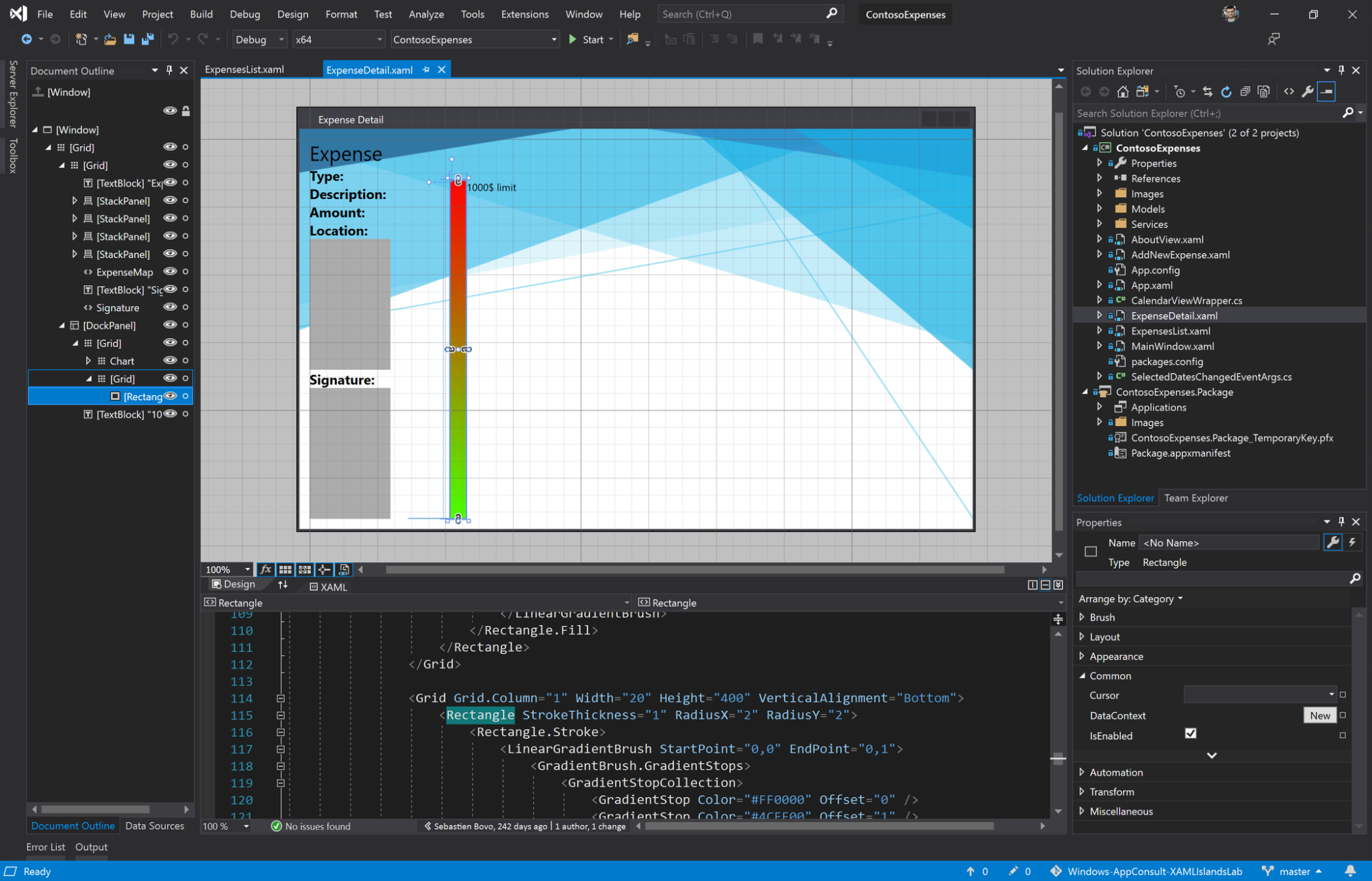
The Windows Forms designer is still in preview, and available as a separate download. It will be added to Visual Studio as part of a later release. The designer currently includes support for the most commonly used controls and low-level functionality. We’ll keep improving the designer with monthly updates. We don’t recommend porting your Windows Forms applications to .NET Core just yet, particularly if you rely on the designer. Please do experiment with the designer preview, and give us feedback.
You can also create and build desktop applications from the command line using the .NET CLI.
For example, you can quickly create a new Windows Forms app:
You can try WPF using the same flow:
We made Windows Forms and WPF open source, back in December 2018. It’s been great to see the community and the Windows Forms and WPF teams working together to improve those UI frameworks. In the case of WPF, we started out with a very small amount of code in the GitHub repo. At this point, almost all of WPF has been published to GitHub, and a few more components will straggle in over time. Like other .NET Core projects, these new repos are part of the .NET Foundation and licensed with the MIT license.
The System.Windows.Forms.DataVisualization package (which includes the chart control) is also available for .NET Core. You can now include this control in your .NET Core WinForms applications. The source for the chart control is available at dotnet/winforms-datavisualization, on GitHub. The control was migrated to ease porting to .NET Core 3, but isn’t a component we expect to update significantly.
Windows Native Interop
Windows offers a rich native API, in the form of flat C APIs, COM and WinRT. We’ve had support for P/Invoke since .NET Core 1.0, and have been adding the ability to CoCreate COM APIs, activate WinRT APIs, and exposed managed code as COM components as part of the .NET Core 3.0 release. We have had many requests for these capabilities, so we know that they will get a lot of use.
Late last year, we announced that we had managed to automate Excel from .NET Core. That was a fun moment. Under the covers, this demo is using COM interop features like NOPIA, object equivalence and custom marshallers. You can now try this and other demos yourself at extension samples.
Managed C++ and WinRT interop have partial support with .NET Core 3.0 and will be included with .NET Core 3.1.
Nullable reference types
C# 8.0 introduces nullable reference types and non-nullable reference types that enable you to make important statements about the properties for reference type variables:
- A reference is not supposed to be null. When variables aren’t supposed to be null, the compiler enforces rules that ensure it is safe to dereference these variables without first checking that it isn’t null.
- A reference may be null. When variables may be null, the compiler enforces different rules to ensure that you’ve correctly checked for a null reference.
This new feature provides significant benefits over the handling of reference variables in earlier versions of C# where the design intent couldn’t be determined from the variable declaration. With the addition of nullable reference types, you can declare your intent more clearly, and the compiler both helps you do that correctly and discover bugs in your code.
See This is how you get rid of null reference exceptions forever, Try out Nullable Reference Types and Nullable reference types to learn more.
Default implementations of interface members
Today, once you publish an interface, it’s game over for changing it: you can’t add members to it without breaking all the existing implementers of it.
With C# 8.0, you can provide a body for an interface member. As a result, if a class that implements the interface doesn’t implement that member (perhaps because it wasn’t there yet when they wrote the code), then the calling code will just get the default implementation instead.
In this example, the class doesn’t have to implement the overload of ILogger, because it is declared with a default implementation. Now you can add new members to existing public interfaces as long as you provide a default implementation for existing implementors to use.
Async streams
You can now over an async stream of data using . This new interface is exactly what you’d expect; an asynchronous version of . The language lets you over tasks to consume their elements. On the production side, you items to produce an async stream. It might sound a bit complicated, but it is incredibly easy in practice.
The following example demonstrates both production and consumption of async streams. The foreach statement is async and itself uses yield return to produce an async stream for callers. This pattern – using — is the recommended model for producing async streams.
In addition to being able to , you can also create async iterators, e.g. an iterator that returns an / that you can both and in. For objects that need to be disposed, you can use , which various framework types implement, such as and .
Index and Range
We’ve created new syntax and types that you can use to describe indexers, for array element access or for any other type that exposes direct data access. This includes support for both a single value — the usual definition of an index — or two values, which describing a range.
is a new type that describes an array index. You can create an from an int that counts from the beginning, or with a prefix operator that counts from the end. You can see both cases in the following example:
is similar, consisting of two values, one for the start and one for the end, and can be written with a x..y range expression. You can then index with a in order to produce a slice of the underlying data, as demonstrated in the following example:
Using Declarations
Are you tired of using statements that require indenting your code? No more! You can now write the following code, which attaches a using declaration to the scope of the current statement block and then disposes the object at the end of it.
Switch Expressions
Anyone who uses C# probably loves the idea of a switch statement, but not the syntax. C# 8 introduces switch expressions, which enable the following:
- terser syntax
- returns a value since it is an expression
- fully integrated with pattern matching
The switch keyword is “infix”, meaning the keyword sits between the tested value (that’s in the first example) and the list of cases, much like expression lambdas.
The first examples uses the lambda syntax for methods, which integrates well with the switch expressions but isn’t required.
There are two patterns at play in this example. o first matches with the Point type pattern and then with the property pattern inside the {curly braces}. The _ describes the discard pattern, which is the same as default for switch statements.
You can go one step further, and rely on tuple deconstruction and parameter position, as you can see in the following example:
In this example, you can see you do not need to define a variable or explicit type for each of the cases. Instead, the compiler can match the tuple being testing with the tuples defined for each of the cases.
All of these patterns enable you to write declarative code that captures your intent instead of procedural code that implements tests for it. The compiler becomes responsible for implementing that boring procedural code and is guaranteed to always do it correctly.
There will still be cases where switch statements will be a better choice than switch expressions and patterns can be used with both syntax styles.
Introducing a fast JSON API
.NET Core 3.0 includes a new family of JSON APIs that enable reader/writer scenarios, random access with a document object model (DOM) and a serializer. You are likely familiar with using Newtonsoft.Json. The new APIs are intended to satisfy many of the same scenarios, but with less memory and faster execution.
You can see the initial motivation and description of the plan in The future of JSON in .NET Core 3.0. This includes James Newton-King, the author of Newtonsoft.Json, explaining why a new API was created, as opposed to extending Newtonsoft.Json. In short, we wanted to build a new JSON API that took advantage of all the new performance capabilities in .NET Core, and delivered performance inline with that. It wasn’t possible to do that in an existing codebase like Newtonsoft.Json while maintaining compatibility.
Let’s take a quick look at the new API, layer by layer.
Utf8JsonReader
is a high-performance, low allocation, forward-only reader for UTF-8 encoded JSON text, read from a . The is a foundational, low-level type, that can be leveraged to build custom parsers and deserializers. Reading through a JSON payload using the new Utf8JsonReader is 2x faster than using the reader from Newtonsoft.Json. It does not allocate until you need to actualize JSON tokens as (UTF-16) strings.
Utf8JsonWriter
provides a high-performance, non-cached, forward-only way to write UTF-8 encoded JSON text from common .NET types like , , and . Like the reader, the writer is a foundational, low-level type, that can be leveraged to build custom serializers. Writing a JSON payload using the new is 30-80% faster than using the writer from and does not allocate.
JsonDocument
provides the ability to parse JSON data and build a read-only Document Object Model (DOM) that can be queried to support random access and enumeration. It is built on top of the . The JSON elements that compose the data can be accessed via the type which is exposed by the as a property called . The contains the JSON array and object enumerators along with APIs to convert JSON text to common .NET types. Parsing a typical JSON payload and accessing all its members using the is 2-3x faster than with very little allocations for data that is reasonably sized (i.e. < 1 MB).
JSON Serializer
layers on top of the high-performance and . It deserializes objects from JSON and serializes objects to JSON. Memory allocations are kept minimal and includes support for reading and writing JSON with asynchronously.
See the documentation for information and samples.
Introducing the new SqlClient
SqlClient is the data provider you use to access Microsoft SQL Server and Azure SQL Database, either through one of the popular .NET O/RMs, like EF Core or Dapper, or directly using the ADO.NET APIs. It will now be released and updated as the Microsoft.Data.SqlClient NuGet package, and supported for both .NET Framework and .NET Core applications. By using NuGet, it will be easier for the SQL team to provide updates to both .NET Framework and .NET Core users.
ARM and IoT Support
We added support for Linux ARM64 this release, after having added support for ARM32 for Linux and Windows in the .NET Core 2.1 and 2.2, respectively. While some IoT workloads take advantage of our existing x64 capabilities, many users had been asking for ARM support. That is now in place, and we are working with customers who are planning large deployments.
Many IoT deployments using .NET are edge devices, and entirely network-oriented. Other scenarios require direct access to hardware. In this release, we added the capability to use serial ports on Linux and take advantage of digital pins on devices like the Raspberry Pi. The pins use a variety of protocols. We added support for GPIO, PWM, I2C, and SPI, to enable reading sensor data, interacting with radios and writing text and images to displays, and many other scenarios.
This functionality is available as part of the following packages:
As part of providing support for GPIO (and friends), we took a look at what was already available. We found APIs for C# and also Python. In both cases, the APIs were wrappers over native libraries, which were often licensed as GPL. We didn’t see a path forward with that approach. Instead, we built a 100% C# solution to implement these protocols. This means that our APIs will work anywhere .NET Core is supported, can be debugged with a C# debugger (via sourcelink), and supports multiple underlying Linux drivers (sysfs, libgpiod, and board-specific). All of the code is licensed as MIT. We see this approach as a major improvement for .NET developers compared to what has existed.
See dotnet/iot to learn more. The best places to start are samples or devices. We have built a few experiments while adding support for GPIO. One of them was validating that we could control an Arduino from a Pi through a serial port connection. That was suprisingly easy. We also spent a lot of time playing with LED matrices, as you can see in this RGB LED Matrix sample. We expect to share more of these experiments over time.
.NET Core runtime roll-forward policy update
The .NET Core runtime, actually the runtime binder, now enables major-version roll-forward as an opt-in policy. The runtime binder already enables roll-forward on patch and minor versions as a default policy. We decided to expose a broader set of policies, which we expected would be important for various scenarios, but did not change the default roll-forward behavior.
There is a new property called , which accepts the following values:
- — Rolls forward to the highest patch version. This disables the policy.
- — Rolls forward to the lowest higher minor version, if the requested minor version is missing. If the requested minor version is present, then the policy is used. This is the default policy.
- — Rolls forward to lowest higher major version, and lowest minor version, if the requested major version is missing. If the requested major version is present, then the policy is used.
- — Rolls forward to highest minor version, even if the requested minor version is present.
- — Rolls forward to highest major and highest minor version, even if requested major is present.
- — Do not roll forward. Only bind to specified version. This policy is not recommended for general use since it disable the ability to roll-forward to the latest patches. It is only recommended for testing.
See Runtime Binding Behavior and dotnet/core-setup #5691 for more information.
Docker and cgroup Limits
Many developers are packaging and running their application with containers. A key scenario is limiting a container’s resources such as CPU or memory. We implemented support for memory limits back in 2017. Unfortunately, we found that the implementation wasn’t aggressive enough to reliably stay under the configured limits and applications were still being OOM killed when memory limits are set (particular <500MB). We have fixed that in .NET Core 3.0. We strongly recommend that .NET Core Docker users upgrade to .NET Core 3.0 due to this improvement.
The Docker resource limits feature is built on top of cgroups, which a Linux kernel feature. From a runtime perspective, we need to target cgroup primitives.
You can limit the available memory for a container with the argument, as shown in the following example that creates an Alpine-based container with a 4MB memory limit (and then prints the memory limit):
We also added made changes to better support CPU limits (). This includes changing the way that the runtime rounds up or down for decimal CPU values. In the case where is set to a value close (enough) to a smaller integer (for example, 1.499999999), the runtime would previously round that value down (in this case, to 1). As a result, the runtime would take advantage of less CPUs than requested, leading to CPU underutilization. By rounding up the value, the runtime augments the pressure on the OS threads scheduler, but even in the worst case scenario ( — previously rounded down to 1, now rounded to 2), we have not observed any overutilization of the CPU leading to performance degradation.
The next step was ensuring that the thread pool honors CPU limits. Part of the algorithm of the thread pool is computing CPU busy time, which is, in part, a function of available CPUs. By taking CPU limits into account when computing CPU busy time, we avoid various heuristics of the threadpool competing with each other: one trying to allocate more threads to increase the CPU busy time, and the other one trying to allocate less threads because adding more threads doesn’t improve the throughput.
Making GC Heap Sizes Smaller by default
While working on improving support for docker memory limits, we were inspired to make more general GC policy updates to improve memory usage for a broader set of applications (even when not running in a container). The changes better align the generation 0 allocation budget with modern processor cache sizes and cache hierarchy.
Damian Edwards on our team noticed that the memory usage of the ASP.NET benchmarks were cut in half with no negative effect on other performance metrics. That’s a staggering improvement! As he says, these are the new defaults, with no change required to his (or your) code (other than adopting .NET Core 3.0).
The memory savings that we saw with the ASP.NET benchmarks may or may not be representative of what you’ll see with your application. We’d like to hear how these changes reduce memory usage for your application.
Better support for many proc machines
Based on .NET’s Windows heritage, the GC needed to implement the Windows concept of processor groups to support machines with 64+ processors. This implementation was made in .NET Framework, 5-10 years ago. With .NET Core, we made the choice initially for the Linux PAL to emulate that same concept, even though it doesn’t exist in Linux. We have since abandoned this concept in the GC and transitioned it exclusively to the Windows PAL.
The GC now exposes a configuration switch, GCHeapAffinitizeRanges, to specify affinity masks on machines with 64+ processors. Maoni Stephens wrote about this change in Making CPU configuration better for GC on machines with > 64 CPUs.
GC Large page support
Large Pages or Huge Pages is a feature where the operating system is able to establish memory regions larger than the native page size (often 4K) to improve performance of the application requesting these large pages.
When a virtual-to-physical address translation occurs, a cache called the Translation lookaside buffer (TLB) is first consulted (often in parallel) to check if a physical translation for the virtual address being accessed is available, to avoid doing a potentially expensive page-table walk. Each large-page translation uses a single translation buffer inside the CPU. The size of this buffer is typically three orders of magnitude larger than the native page size; this increases the efficiency of the translation buffer, which can increase performance for frequently accessed memory. This win can be even more significant in a virtual machine, which has a two-layer TLB.
The GC can now be configured with the GCLargePages opt-in feature to choose to allocate large pages on Windows. Using large pages reduces TLB misses therefore can potentially increase application perf in general, however, the feature has its own set of limitations that should be considered. Bing has experimented with this feature and seen performance improvements.
.NET Core Version APIs
We have improved the .NET Core version APIs in .NET Core 3.0. They now return the version information you would expect. These changes while they are objectively better are technically breaking and may break applications that rely on existing version APIs for various information.
You can now get access to the following version information:
Event Pipe improvements
Event Pipe now supports multiple sessions. This means that you can consume events with EventListener in-proc and simultaneously have out-of-process event pipe clients.
New Perf Counters added:
- % Time in GC
- Gen 0 Heap Size
- Gen 1 Heap Size
- Gen 2 Heap Size
- LOH Heap Size
- Allocation Rate
- Number of assemblies loaded
- Number of ThreadPool Threads
- Monitor Lock Contention Rate
- ThreadPool Work Items Queue
- ThreadPool Completed Work Items Rate
Profiler attach is now implemented using the same Event Pipe infrastructure.
See Playing with counters from David Fowler to get an idea of what you can do with event pipe to perform your own performance investigations or just monitor application status.
See dotnet-counters to install the dotnet-counters tool.
HTTP/2 Support
We now have support for HTTP/2 in HttpClient. The new protocol is a requirement for some APIs, like gRPC and Apple Push Notification Service. We expect more services to require HTTP/2 in the future. ASP.NET also has support for HTTP/2.
Note: the preferred HTTP protocol version will be negotiated via TLS/ALPN and HTTP/2 will only be used if the server selects to use it.
Tiered Compilation
Tiered compilation was added as an opt-in feature in .NET Core 2.1. It’s a feature that enables the runtime to more adaptively use the Just-In-Time (JIT) compiler to get better performance, both at startup and to maximize throughput. It is enabled by default with .NET Core 3.0. We made a lot of improvements to the feature over the last year, including testing it with a variety of workloads, including websites, PowerShell Core and Windows desktop apps. The performance is a lot better, which is what enabled us to enable it by default.
IEEE Floating-point improvements
Floating point APIs have been updated to comply with IEEE 754-2008 revision. The goal of the .NET Core floating point project is to expose all “required” operations and ensure that they are behaviorally compliant with the IEEE spec.
Parsing and formatting fixes:
- Correctly parse and round inputs of any length.
- Correctly parse and format negative zero.
- Correctly parse Infinity and NaN by performing a case-insensitive check and allowing an optional preceding where applicable.
New Math APIs:
- — corresponds to the and IEEE operations. They return the smallest floating-point number that compares greater or lesser than the input (respectively). For example, would return .
- — corresponds to the and IEEE operations, they return the value that is greater or lesser in magnitude of the two inputs (respectively). For example, would return .
- — corresponds to the IEEE operation which returns an integral value, it returns the integral base-2 log of the input parameter. This is effectively the same as , but done with minimal rounding error.
- — corresponds to the IEEE operation which takes an integral value, it returns effectively , but is done with minimal rounding error.
- — corresponds to the IEEE operation, it returns the base-2 logarithm. It minimizes rounding error.
- — corresponds to the IEEE operation, it performs a fused multiply add. That is, it does as a single operation, there-by minimizing the rounding error. An example would be which returns . The regular returns .
- — corresponds to the IEEE operation, it returns the value of , but with the sign of .
.NET Platform Dependent Intrinsics
We’ve added APIs that allow access to certain performance-oriented CPU instructions, such as the SIMD or Bit Manipulation instruction sets. These instructions can help achieve big performance improvements in certain scenarios, such as processing data efficiently in parallel. In addition to exposing the APIs for your programs to use, we have begun using these instructions to accelerate the .NET libraries too.
The following CoreCLR PRs demonstrate a few of the intrinsics, either via implementation or use:
For more information, take a look at .NET Platform Dependent Intrinsics, which defines an approach for defining this hardware infrastructure, allowing Microsoft, chip vendors or any other company or individual to define hardware/chip APIs that should be exposed to .NET code.
Supporting TLS 1.3 and OpenSSL 1.1.1 now Supported on Linux
NET Core can now take advantage of TLS 1.3 support in OpenSSL 1.1.1. There are multiple benefits of TLS 1.3, per the OpenSSL team:
- Improved connection times due to a reduction in the number of round trips required between the client and server
- Improved security due to the removal of various obsolete and insecure cryptographic algorithms and encryption of more of the connection handshake
.NET Core 3.0 is capable of utilizing OpenSSL 1.1.1, OpenSSL 1.1.0, or OpenSSL 1.0.2 (whatever the best version found is, on a Linux system). When OpenSSL 1.1.1 is available, the SslStream and HttpClient types will use TLS 1.3 when using SslProtocols.None (system default protocols), assuming both the client and server support TLS 1.3.
.NET Core will support TLS 1.3 on Windows and macOS — we expect automatically — when support becomes available.
Cryptography
We added support for and ciphers, implemented via and . These algorithms are both Authenticated Encryption with Association Data (AEAD) algorithms, and the first Authenticated Encryption (AE) algorithms added to .NET Core.
NET Core 3.0 now supports the import and export of asymmetric public and private keys from standard formats, without needing to use an X.509 certificate.
All key types (RSA, DSA, ECDsa, ECDiffieHellman) support the X.509 SubjectPublicKeyInfo format for public keys, and the PKCS#8 PrivateKeyInfo and PKCS#8 EncryptedPrivateKeyInfo formats for private keys. RSA additionally supports PKCS#1 RSAPublicKey and PKCS#1 RSAPrivateKey. The export methods all produce DER-encoded binary data, and the import methods expect the same; if a key is stored in the text-friendly PEM format the caller will need to base64-decode the content before calling an import method.
PKCS#8 files can be inspected with the class.
PFX/PKCS#12 files can be inspected and manipulated with and , respectively.
New Japanese Era (Reiwa)
On May 1st, 2019, Japan started a new era called Reiwa. Software that has support for Japanese calendars, like .NET Core, must be updated to accommodate Reiwa. .NET Core and .NET Framework have been updated and correctly handle Japanese date formatting and parsing with the new era.
.NET relies on operating system or other updates to correctly process Reiwa dates. If you or your customers are using Windows, download the latest updates for your Windows version. If running macOS or Linux, download and install ICU version 64.2, which has support the new Japanese era.
Handling a new era in the Japanese calendar in .NET blog has more information about .NET support for the new Japanese era.
Assembly Load Context Improvements
Enhancements to AssemblyLoadContext:
- Enable naming contexts
- Added the ability to enumerate ALCs
- Added the ability to enumerate assemblies within an ALC
- Made the type concrete – so instantiation is easier (no requirement for custom types for simple scenarios)
See dotnet/corefx #34791 for more details. The appwithalc sample demonstrates these new capabilities.
By using along with a custom , an application can load plugins so that each plugin’s dependencies are loaded from the correct location, and one plugin’s dependencies will not conflict with another. The AppWithPlugin sample includes plugins that have conflicting dependencies and plugins that rely on satellite assemblies or native libraries.
Assembly Unloadability
Assembly unloadability is a new capability of AssemblyLoadContext. This new feature is largely transparent from an API perspective, exposed with just a few new APIs. It enables a loader context to be unloaded, releasing all memory for instantiated types, static fields and for the assembly itself. An application should be able to load and unload assemblies via this mechanism forever without experiencing a memory leak.
We expect this new capability to be used for the following scenarios:
- Plugin scenarios where dynamic plugin loading and unloading is required.
- Dynamically compiling, running and then flushing code. Useful for web sites, scripting engines, etc.
- Loading assemblies for introspection (like ReflectionOnlyLoad), although MetadataLoadContext will be a better choice in many cases.
Assembly Metadata Reading with MetadataLoadContext
We added , which enables reading assembly metadata without affecting the caller’s application domain. Assemblies are read as data, including assemblies built for different architectures and platforms than the current runtime environment. MetadataLoadContext overlaps with the ReflectionOnlyLoad type, which is only available in the .NET Framework.
is available in the System.Reflection.MetadataLoadContext package. It is a .NET Standard 2.0 package.
Scenarios for MetadataLoadContext include design-time features, build-time tooling, and runtime light-up features that need to inspect a set of assemblies as data and have all file locks and memory freed after inspection is performed.
Native Hosting sample
The team posted a Native Hosting sample. It demonstrates a best practice approach for hosting .NET Core in a native application.
As part of .NET Core 3.0, we now expose general functionality to .NET Core native hosts that was previously only available to .NET Core managed applications through the officially provided .NET Core hosts. The functionality is primarily related to assembly loading. This functionality should make it easier to produce native hosts that can take advantage of the full feature set of .NET Core.
Other API Improvements
We optimized , and related types that were introduced in .NET Core 2.1. Common operations such as span construction, slicing, parsing, and formatting now perform better. Additionally, types like String have seen under-the-cover improvements to make them more efficient when used as keys with and other collections. No code changes are required to enjoy these improvements.
The following improvements are also new:
- Brotli support built-in to HttpClient
- ThreadPool.UnsafeQueueWorkItem(IThreadPoolWorkItem)
- Unsafe.Unbox
- CancellationToken.Unregister
- Complex arithmetic operators
- Socket APIs for TCP keep alive
- StringBuilder.GetChunks
- IPEndPoint parsing
- RandomNumberGenerator.GetInt32
- System.Buffers.SequenceReader
Applications now have native executables by default
.NET Core applications are now built with native executables. This is new for framework-dependent application. Until now, only self-contained applications had executables.
You can expect the same things with these executables as you would other native executables, such as:
- You can double click on the executable to start the application.
- You can launch the application from a command prompt, using , on Windows, and , on Linux and macOS.
The executable that is generated as part of the build will match your operating system and CPU. For example, if you are on a Linux x64 machine, the executable will only work on that kind of machine, not on a Windows machine and not on a Linux ARM machine. That’s because the executables are native code (just like C++). If you want to target another machine type, you need to publish with a runtime argument. You can continue to launch applications with the command, and not use native executables, if you prefer.
Optimize your .NET Core apps with ReadyToRun images
You can improve the startup time of your .NET Core application by compiling your application assemblies as ReadyToRun (R2R) format. R2R is a form of ahead-of-time (AOT) compilation. It is a publish-time, opt-in feature in .NET Core 3.0.
R2R binaries improve startup performance by reducing the amount of work the JIT needs to do as your application is loading. The binaries contain similar native code as what the JIT would produce, giving the JIT a bit of a vacation when performance matters most (at startup). R2R binaries are larger because they contain both intermediate language (IL) code, which is still needed for some scenarios, and the native version of the same code, to improve startup.
To enable the ReadyToRun compilation:
- Set the property to .
- Publish using an explicit .
Note: When the application assemblies get compiled, the native code produced is platform and architecture specific (which is why you have to specify a valid RuntimeIdentifier when publishing).
Here’s an example:
And publish using the following command:
Note: The can be set to another operating system or chip. It can also be set in the project file.
Assembly linking
The .NET core 3.0 SDK comes with a tool that can reduce the size of apps by analyzing IL and trimming unused assemblies. It is another publish-time opt-in feature in .NET Core 3.0.
With .NET Core, it has always been possible to publish self-contained apps that include everything needed to run your code, without requiring .NET to be installed on the deployment target. In some cases, the app only requires a small subset of the framework to function and could potentially be made much smaller by including only the used libraries.
We use the IL linker to scan the IL of your application to detect which code is actually required, and then trim unused framework libraries. This can significantly reduce the size of some apps. Typically, small tool-like console apps benefit the most as they tend to use fairly small subsets of the framework and are usually more amenable to trimming.
To use the linker:
- Set the property to .
- Publish using an explicit .
Here’s an example:
And publish using the following command:
Note: The can be set to another operating system or chip. It can also be set in the project file.
The publish output will include a subset of the framework libraries, depending on what the application code calls. For a helloworld app, the linker reduces the size from ~68MB to ~28MB.
Applications or frameworks (including ASP.NET Core and WPF) that use reflection or related dynamic features will often break when trimmed, because the linker doesn’t know about this dynamic behavior and usually can’t determine which framework types will be required for reflection at run time. To trim such apps, you need to tell the linker about any types needed by reflection in your code, and in any packages or frameworks that you depend on. Be sure to test your apps after trimming. We are working on improving this experience for .NET 5.
For more information about the IL Linker, see the documentation, or visit the mono/linker repo.
Note: In previous versions of .NET Core, ILLink.Tasks was shipped as an external NuGet package and provided much of the same functionality. It is no longer supported – please update to the .NET Core 3.0 SDK and try the new experience!
The linker and ReadyToRun compiler can be used for the same application. In general, the linker makes your application smaller, and then the ready-to-run compiler will make it a bit larger again, but with a significant performance win. It is worth testing in various configurations to understand the impact of each option.
Publishing single-file executables
You can now publish a single-file executable with . This form of single EXE is effectively a self-extracting executable. It contains all dependencies, including native dependencies, as resources. At startup, it copies all dependencies to a temp directory, and loads them for there. It only needs to unpack dependencies once. After that, startup is fast, without any penalty.
You can enable this publishing option by adding the property to your project file or by adding a new switch on the commandline.
To produce a self-contained single EXE application, in this case for 64-bit Windows:
Note: The can be set to another operating system or chip. It can also be set in the project file.
See Single file bundler for more information.
Assembly trimmer, ahead-of-time compilation (via crossgen) and single file bundling are all new features in .NET Core 3.0 that can be used together or separately.
We expect that some of you will prefer single exe provided by an ahead-of-time compiler, as opposed to the self-extracting-executable approach that we are providing in .NET Core 3.0. The ahead-of-time compiler approach will be provided as part of the .NET 5 release.
dotnet build now copies dependencies
dotnet build now copies NuGet dependencies for your application from the NuGet cache to your build output folder during the build operation. Until this release,those dependencies were only copied as part of dotnet publish. This change allows you to xcopy your build output to different machines.
There are some operations, like linking and razor page publishing that require publishing.
.NET Core Tools — local installation
.NET Core tools has been updated to allow local installation. They have advantages over global tools, which were added in .NET Core 2.1.
Local installation enables the following:
- Limit the scope by which a tool can be used.
What’s New in the Mobile Net Switch v3.1 serial key or number?
Screen Shot
System Requirements for Mobile Net Switch v3.1 serial key or number
- First, download the Mobile Net Switch v3.1 serial key or number
-
You can download its setup from given links:

Mobile Net Switch v3.1 serial key or number & Apps for Laptop & PC Free Download

Mobile Net Switch v3.1 serial key or number& Free Download
